Ghostcat Tomcat文件读取和文件包含漏洞(CVE-2020-1938)
介绍
漏洞信息
由于 Tomact AJP 协议的设计缺陷,攻击者可以通过漏洞读取 webapp 目录下的任意文件,或者通过文件包含 getshell 。
编号:CNVD-2020-10487 / CVE-2020-1938
外号:Ghostcat
Tomcat的AJP是默认开启的,一般来说只要发现目标机器开放了8009端口并且Tomcat的版本处于受影响版本中,就会有漏洞。
AJP的介绍
在 AJP 协议中,请求参数是以二进制格式传输的。在处理 AJP 请求时,Tomcat 会将请求参数解析为一个名值对的列表,并将其转换为 HTTP 请求的属性,以便应用服务器更好处理请求。
AJP 协议设计的主要目的就是快,不过现在主要用于反向代理,就是其它的 web 服务器(例如 Apache 作为客户端到 Tomcat 的中间件,客户端连接 Apache 时采用 http 协议,Apache 再连接后台的 Tomcat 时采用 AJP 协议(也可以不用)。你可以会好奇为什么客户端不直接使用 AJP 协议,因为浏览器不支持,浏览器采用的是更通用的 http 协议。
影响版本
1 | Apache Tomcat 9.x < 9.0.31 |
poc
这里网上有很多工具,这里就不再重新分析 AJP 协议来造轮子了。后面都是基于工具 https://github.com/00theway/Ghostcat-CNVD-2020-10487 来验证漏洞的。
用法:
1 | 文件读取 |
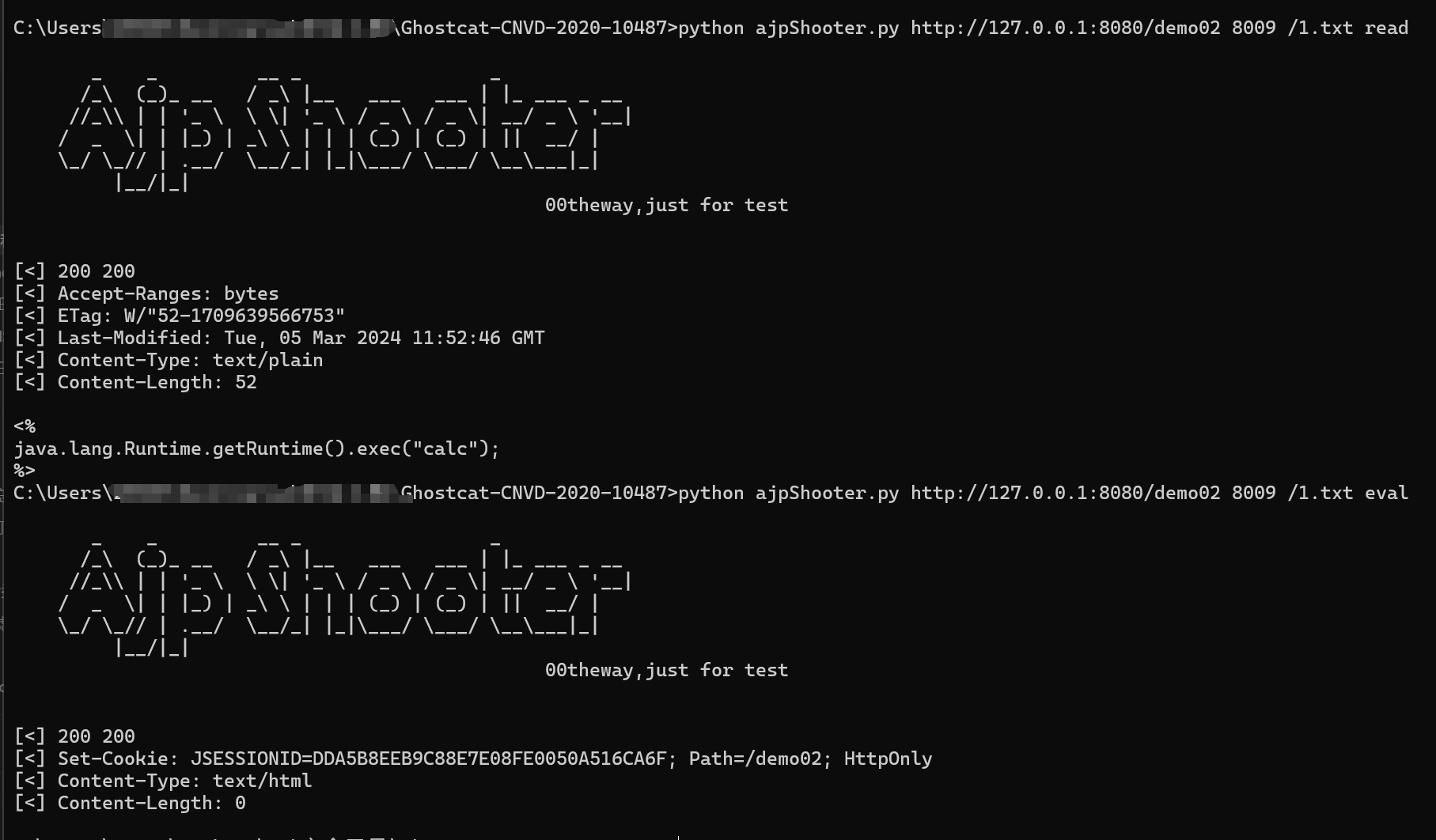
漏洞分析
漏洞触发点
这里以 Tomcat 8.5.42 的源代码来分析调试。
由于我们刚开始对这个漏洞的触发点一无所知,只知道 poc ,所以可以先通过 github 的 diff 功能看一下修复了漏洞后的版本做了哪些修改。
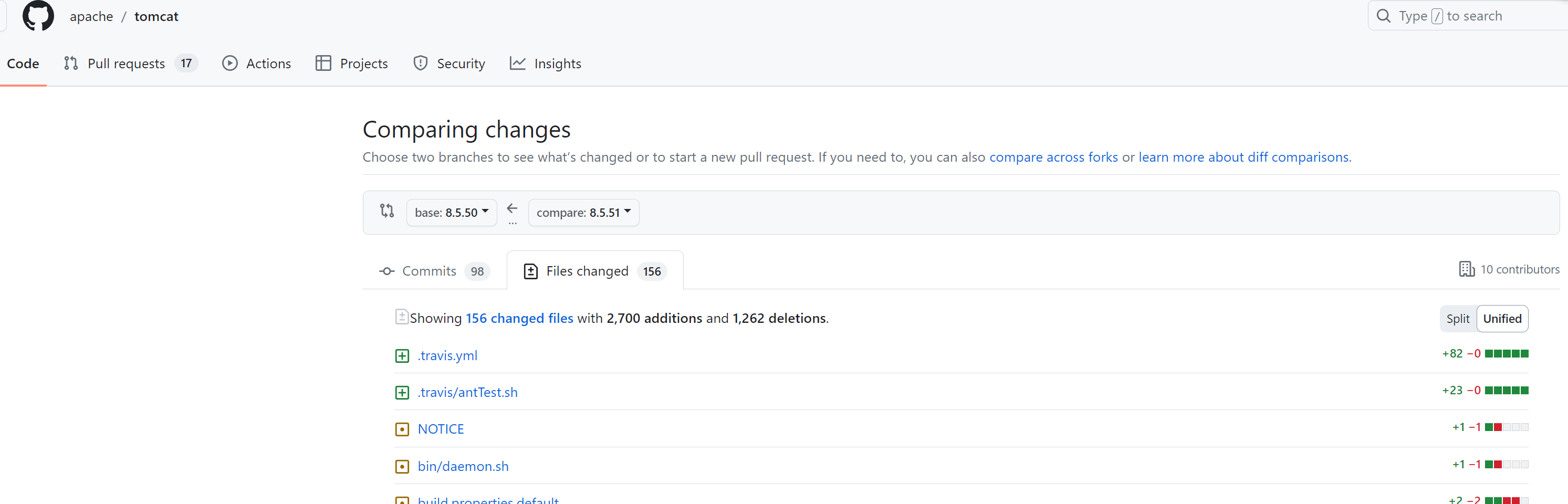
通过代码对比功能我们可以看到 tomcat 从 8.5.50 版本升级到 8.5.51 版本一共更改了 156 个文件。
通过 ajp 关键字可以发现 ajp 相关的源代码修改集中在 org.apache.coyote.ajp 包里。
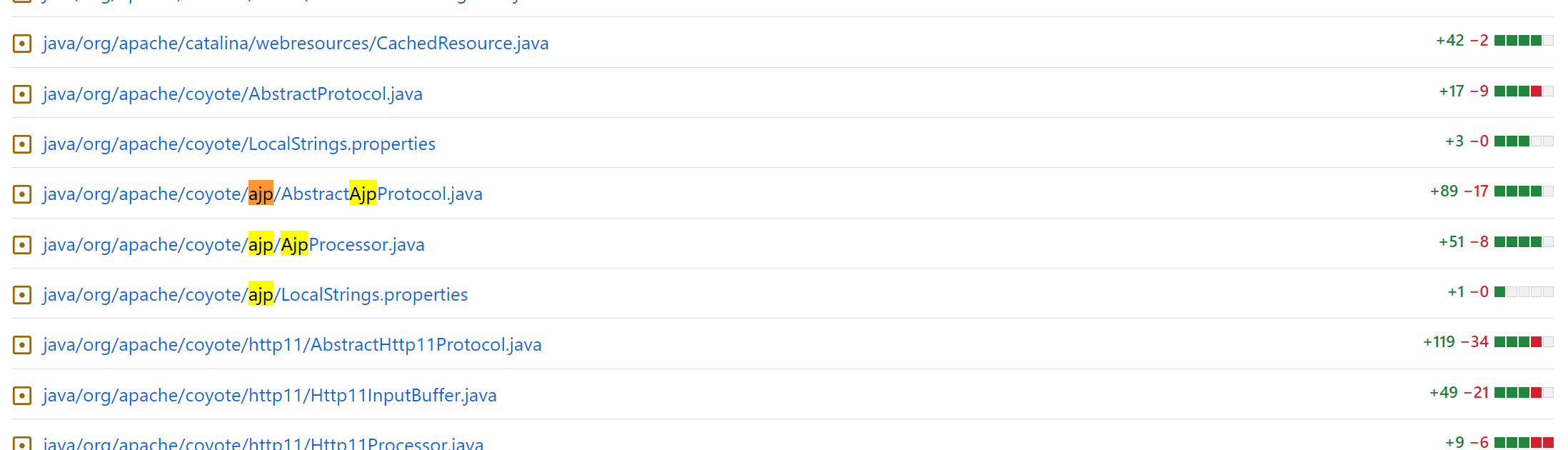
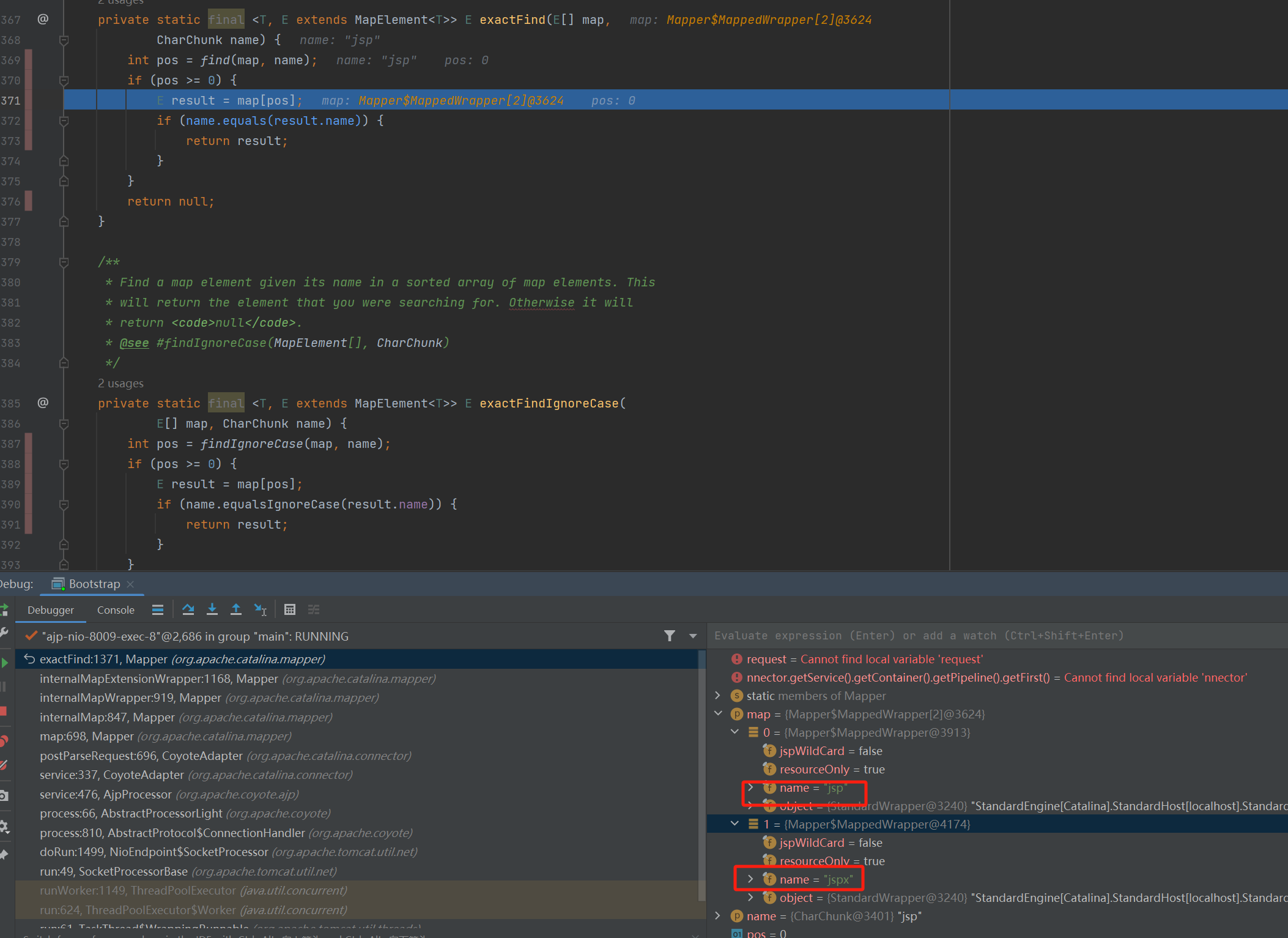
进一步分析改动的源代码,我们可以发现 org.apache.coyote.ajp.AjpProcessor 中的 prepareRequest() 方法改动的比较大。因此过会调试 Tomcat 源码的时候可以在这个方法打上断点来分析分析。
发现当我们发送 poc 时,确实可以在这个方法断住。
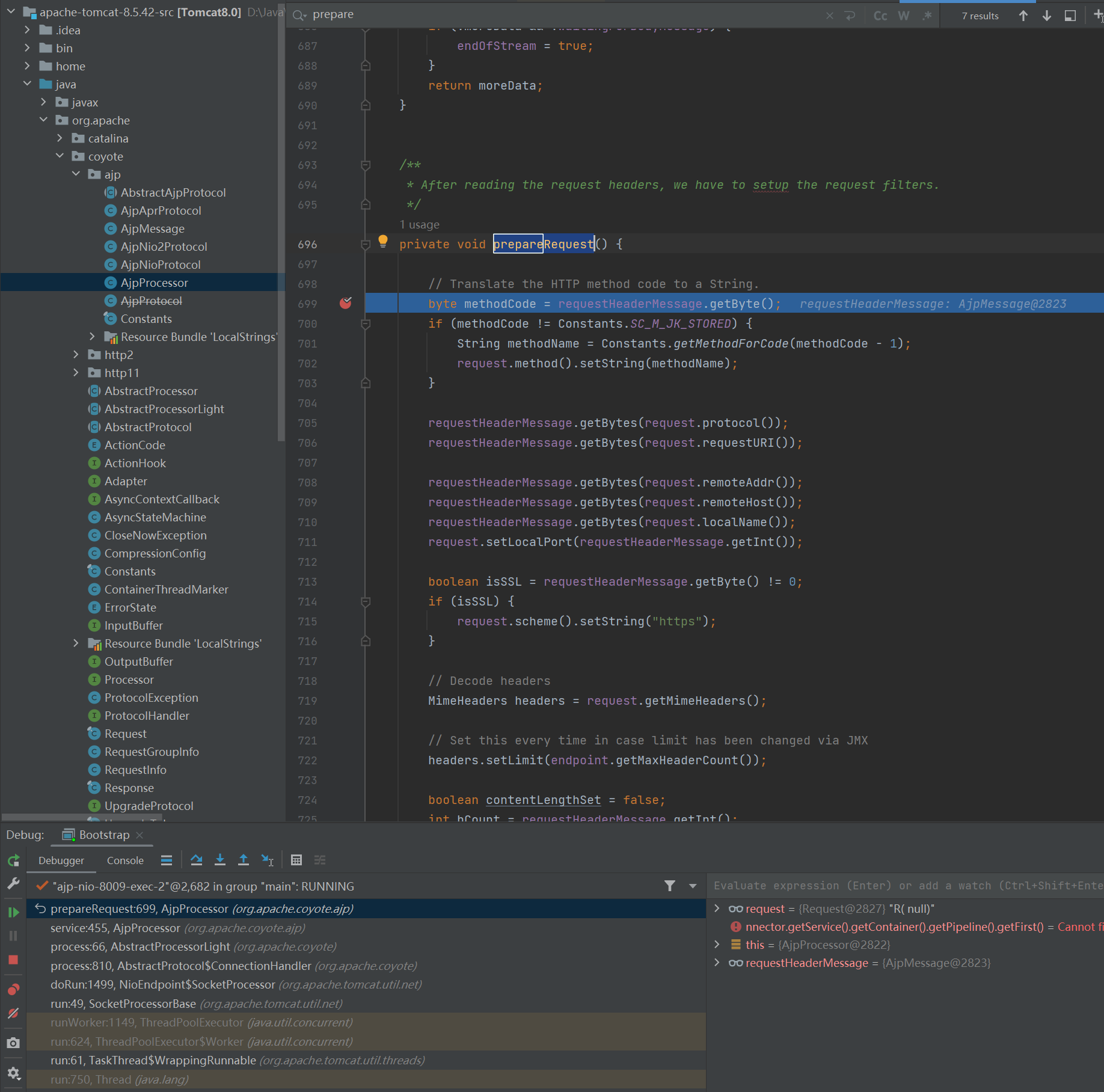
此外,由于这里的漏洞和文件读取相关,因此肯定会用到
java.io.File,所以我们可以给File的构造方法的开头都打上断点,看什么时候进入的参数是poc读取的文件。不过这里要先运行起来后再打断点,不然File的断点会比较多。
发现也成功断住了,这样就很容易看出来漏洞的触发点在哪里了。
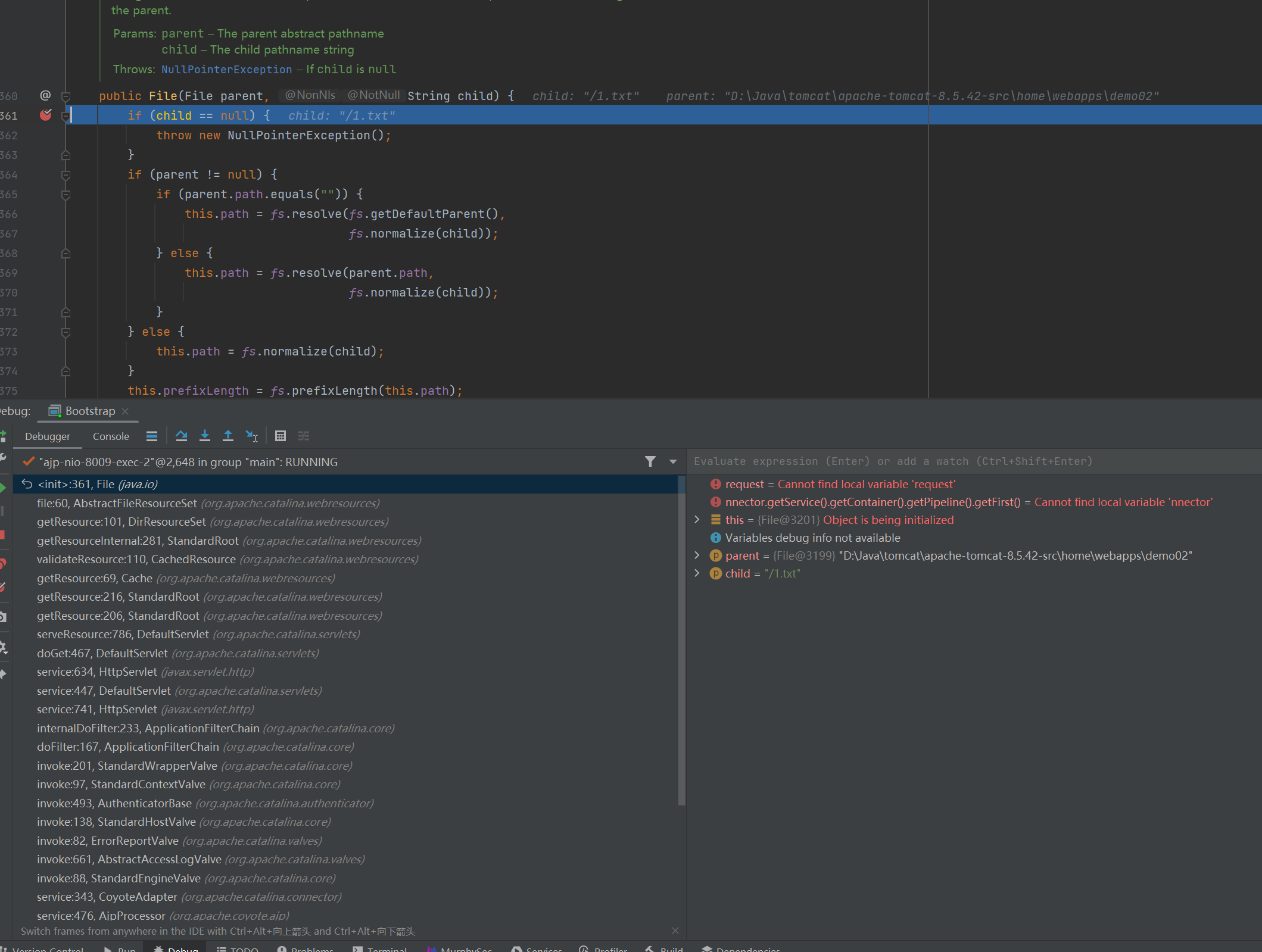
发现漏洞的关键是请求交给到了 org.apache.catalina.servlets.DefaultServlet 来处理。
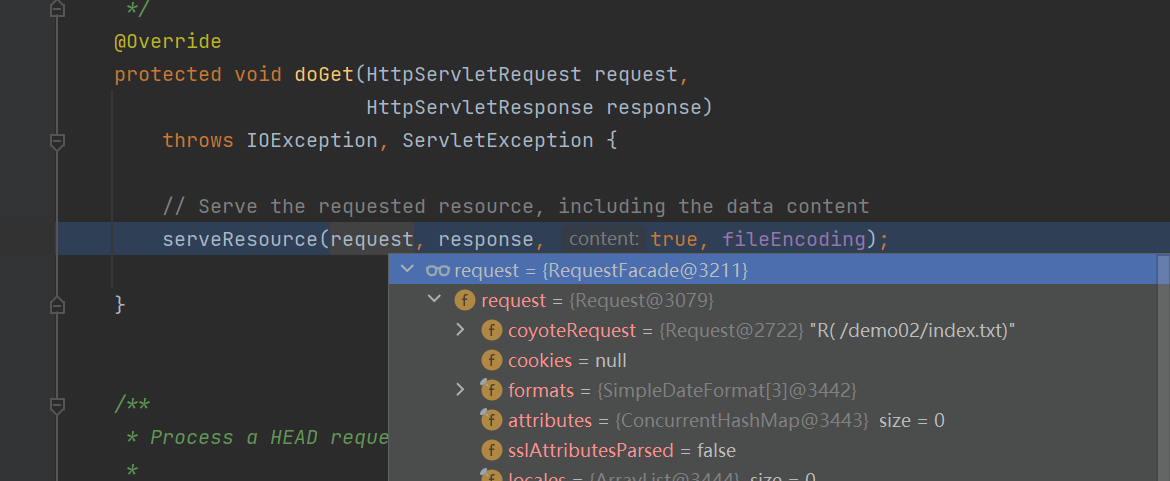
而在这个类在处理请求的时候会在 getRelativePath() 中读取 request 中的 RequestDispatcher.INCLUDE_SERVLET_PATH 属性并返回,交给 resources.getResource() 方法读取对应的文件内容,并在最后返回到 response 中。
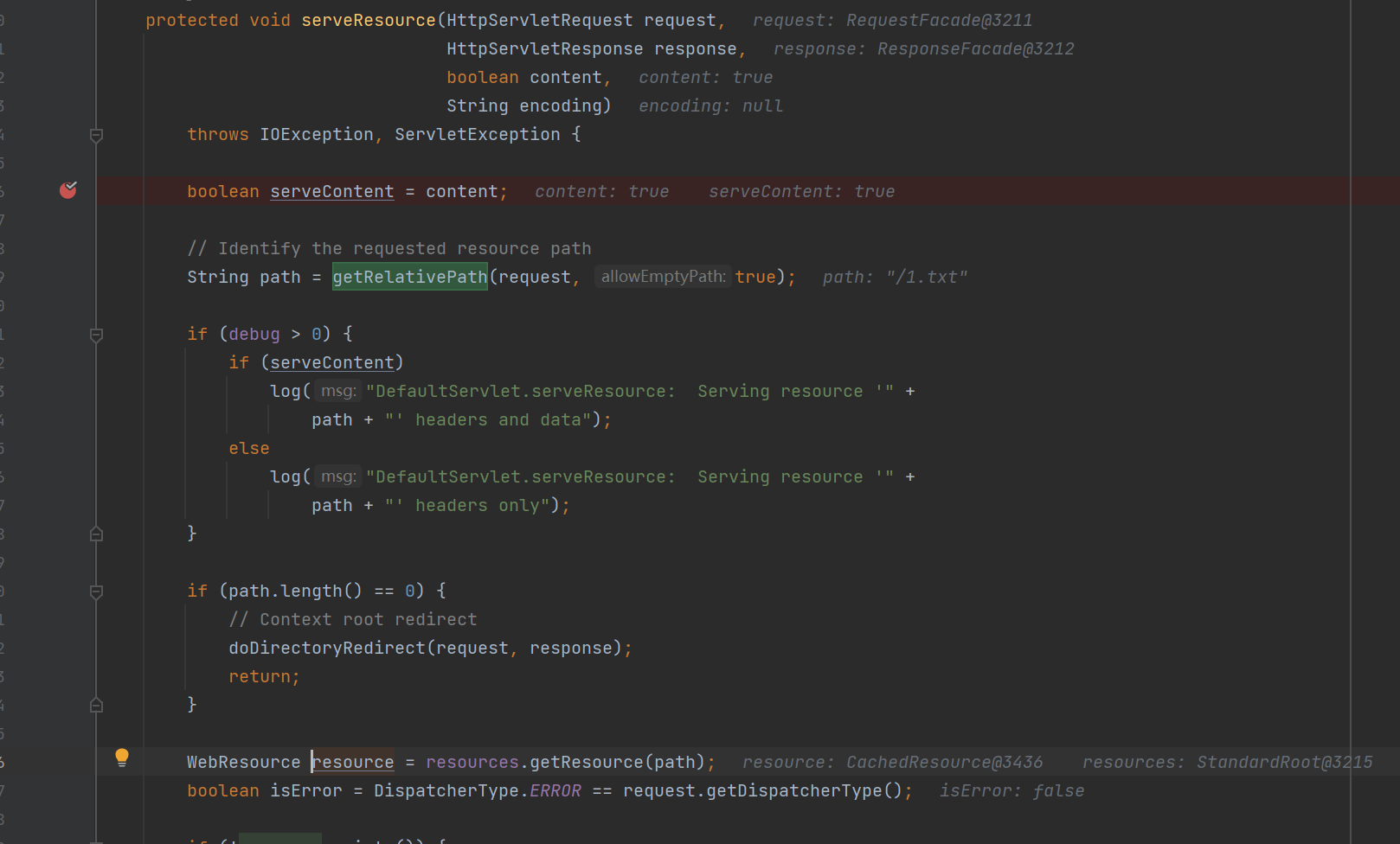
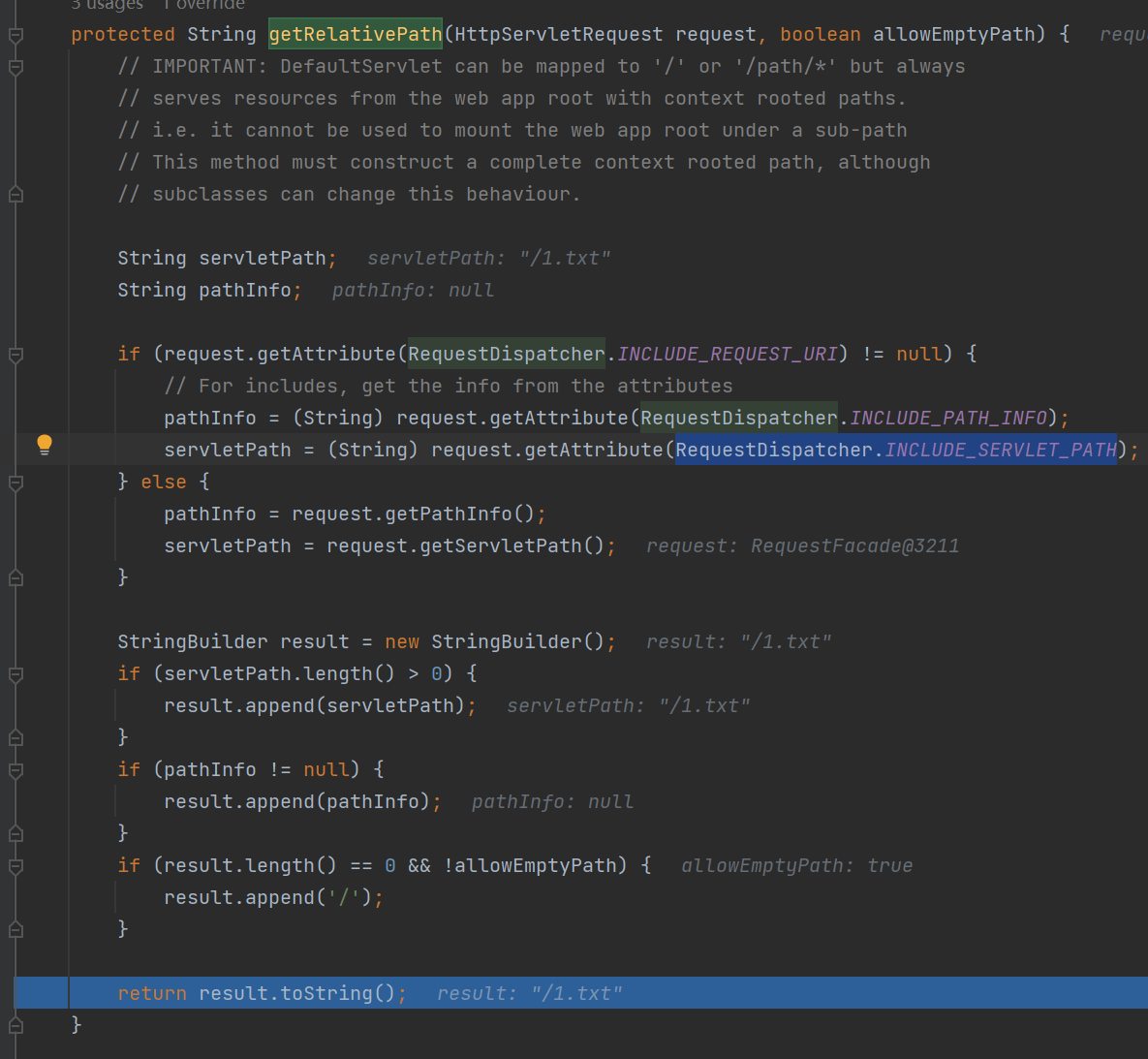
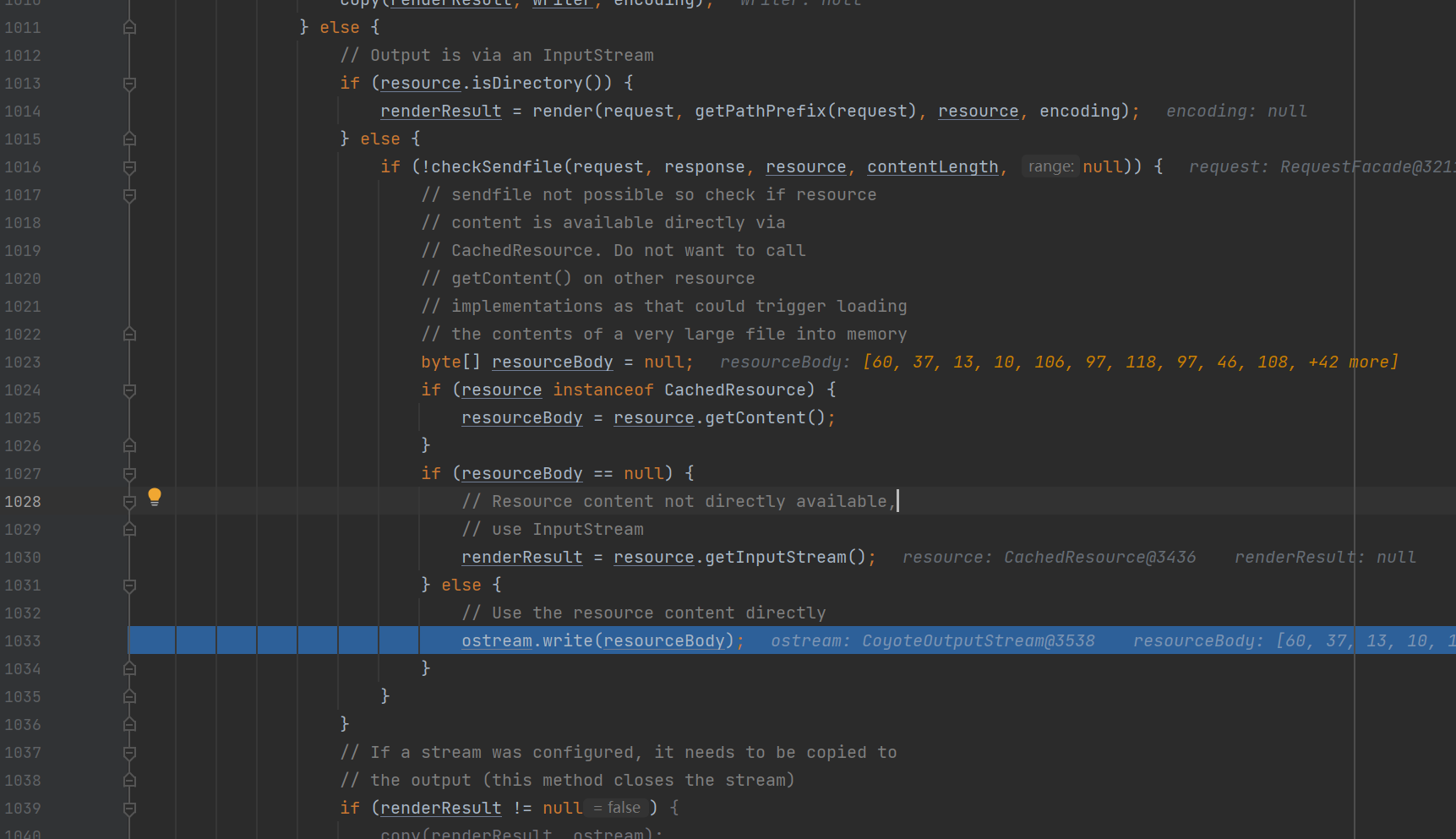
webapps目录下任意文件读取
这里我们就会好奇一点,这里
Tomcat的DefaultServlet是做什么的,并且请求为什么会交给这个Servlet进行处理。
根据查找的资料可以知道:
DefaultServlet为默认的Servlet,当客户端请求不能匹配其他所有Servlet时,将由这个Servlet处理。DefaultServlet主要用于处理静态资源,如HTML、图片、CSS、JS文件等,而且为了提升服务器性能,Tomcat会对访问文件进行缓存。
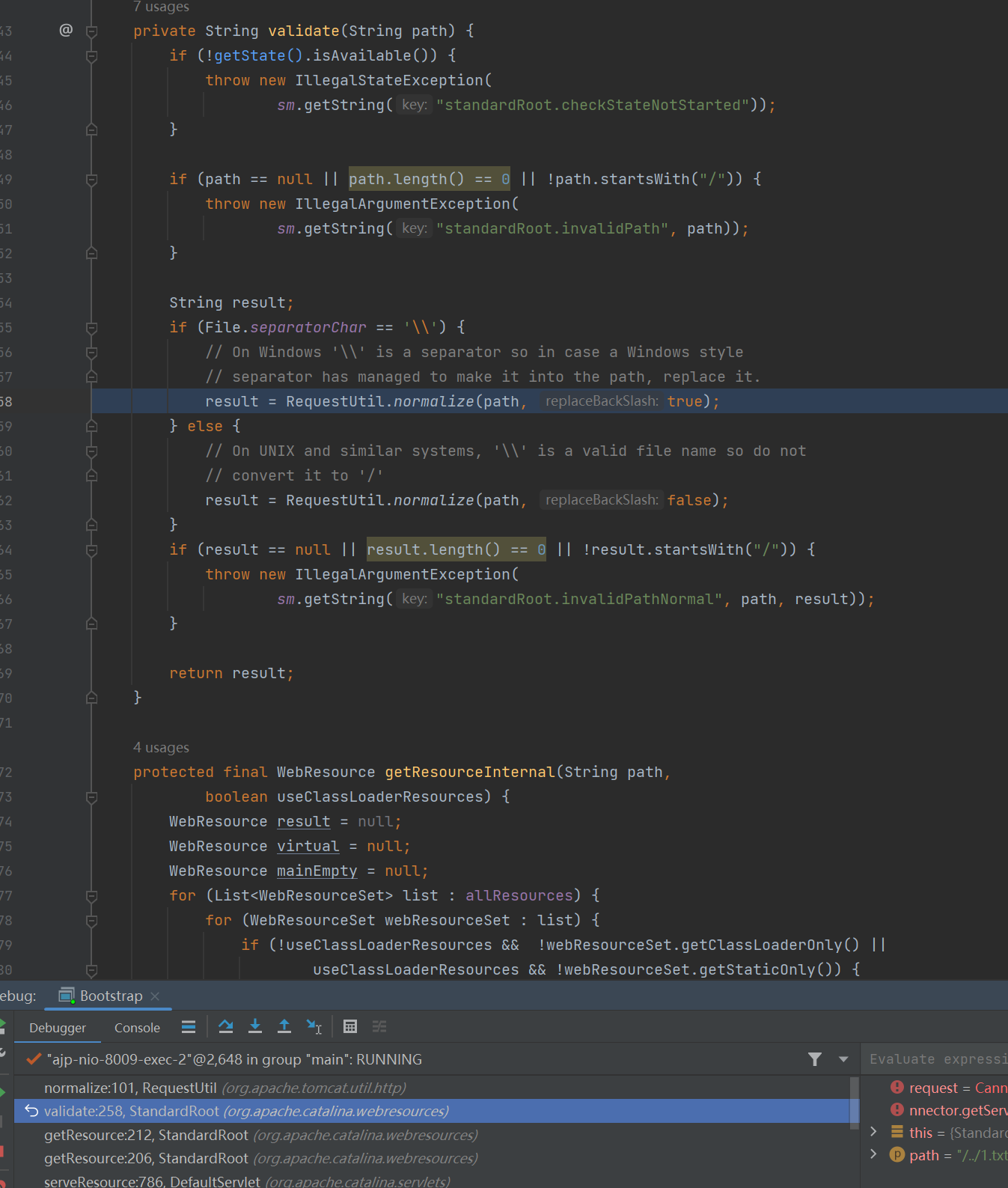
但是我们知道,正常情况下 DefaultServlet 是不应该能够读取 WEB-INF 和 META-INF 目录下的内容的,但是这里的 poc 是可以的,这里是怎么做到的?我们先来分析正常情况下,Tomcat 是怎么防止上面两个目录下的内容被读取的。
正常访问时,在
StandardContextValve.invoke()中会判断request中的requestPath属性(其值等于去掉了项目名后的URI)是否等于或以/META-INF或者/WEB-INF开头,如果是就终止请求,返回404。
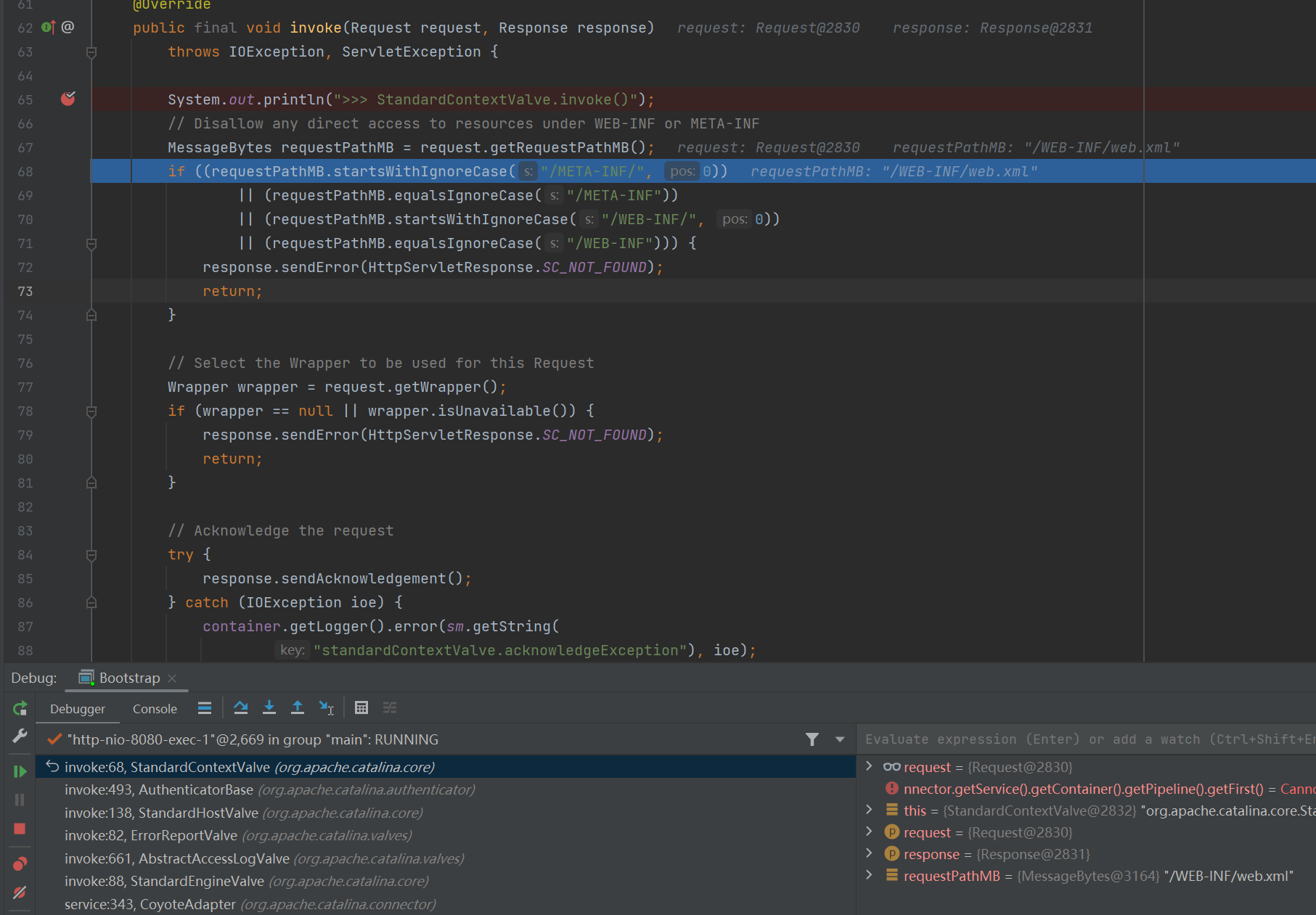
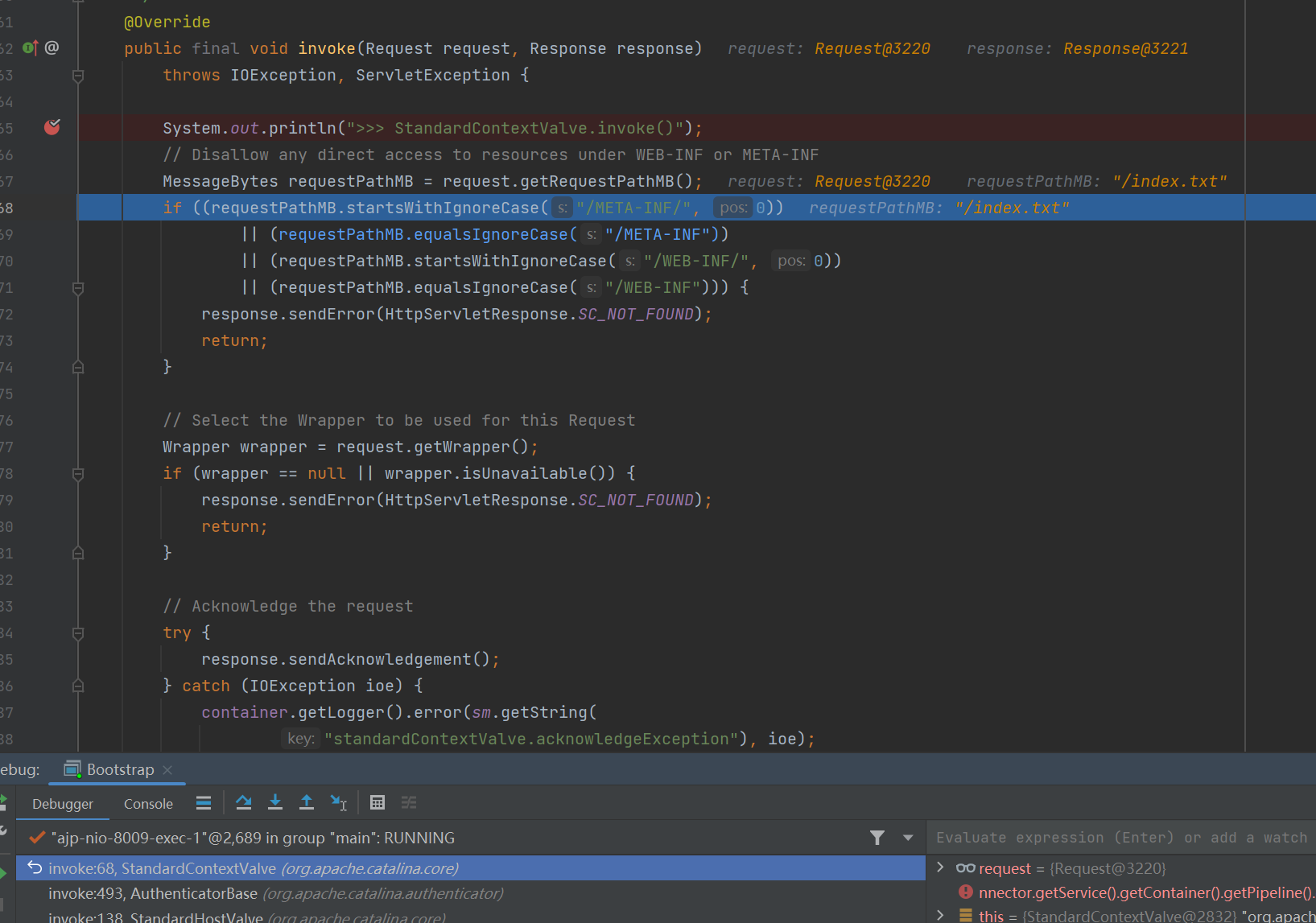
然后我们再观察漏洞情况下这里的参数。发现即使我们目标读取的文件是 /WEB-INF/web.xml ,但是这里的 requestPath 却是 /index.txt 。
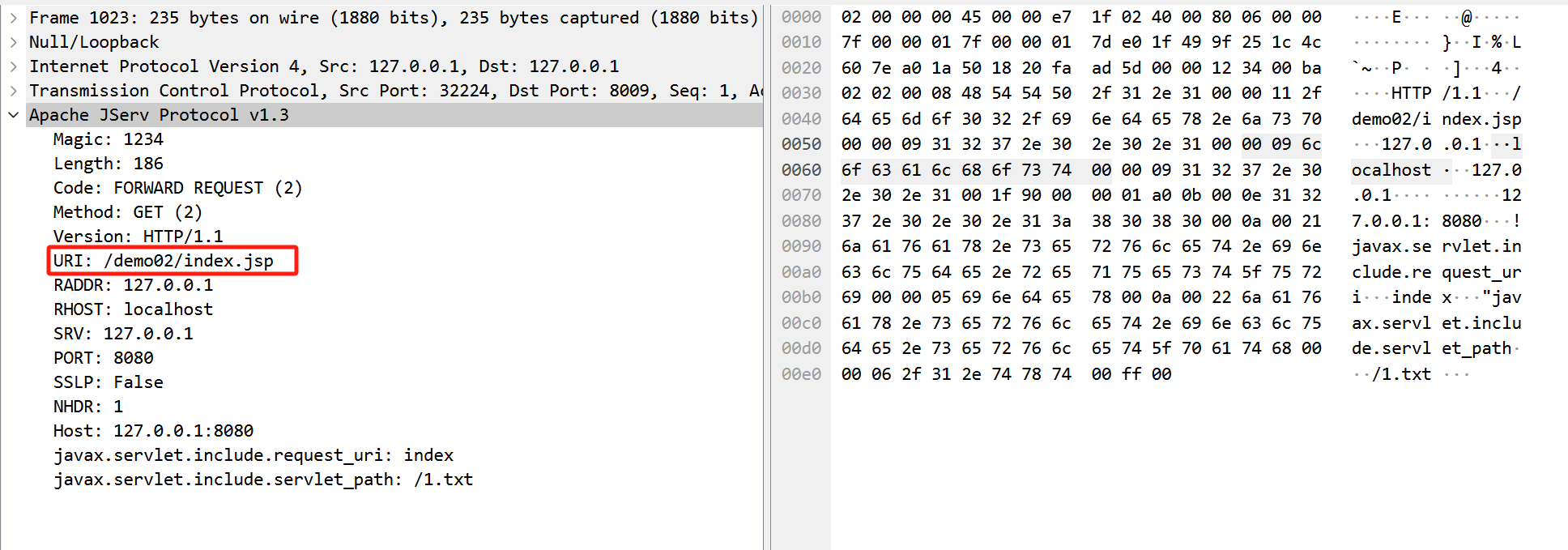
接着我们来抓包看一下上面的 poc 到底发了什么恶意的数据给 Tomcat 。
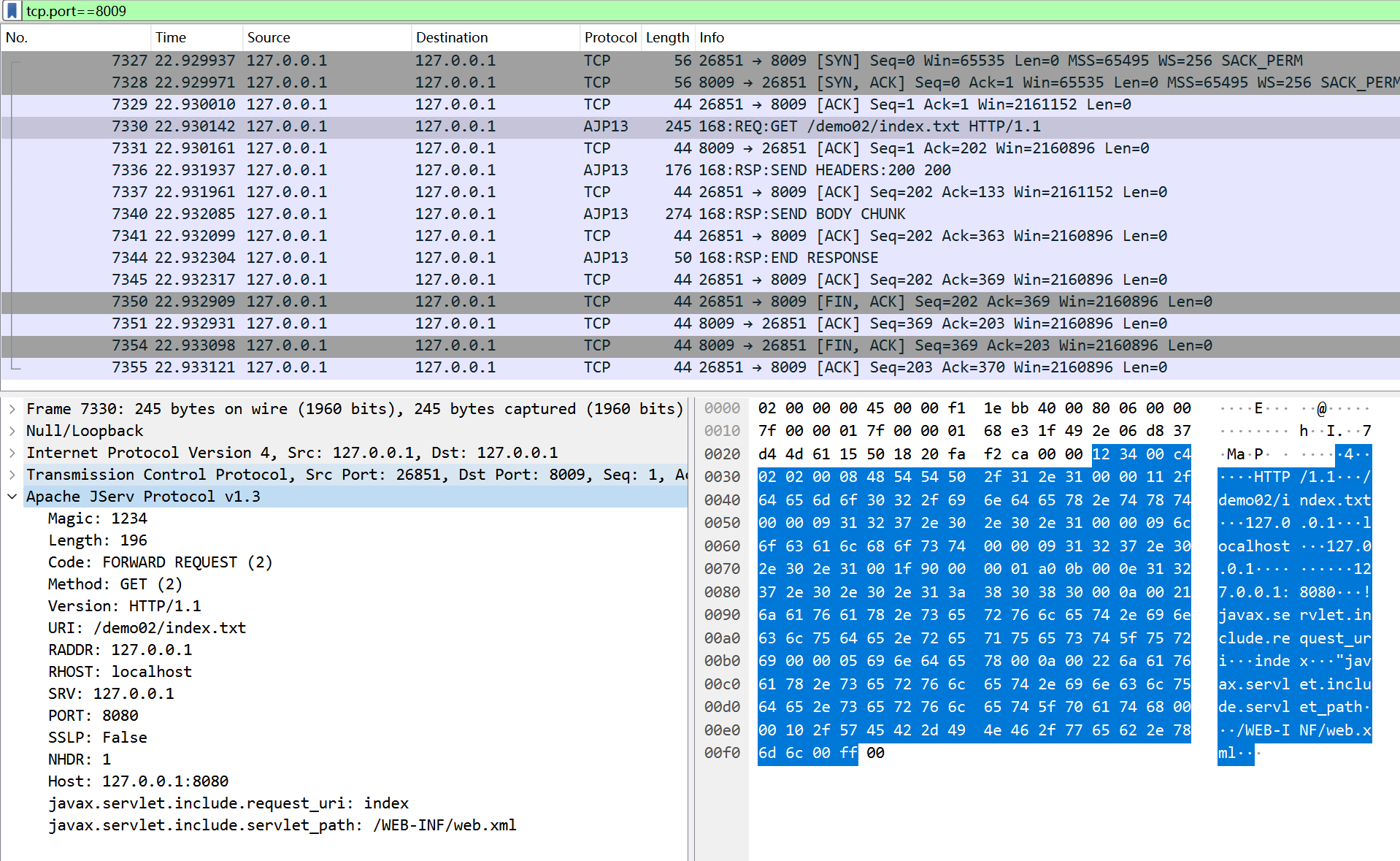
可以发现 index.txt 是 AJP 协议数据包中 URI字段的内容,而我们实际读取的文件内容在 javax.servlet.include.request_path 字段中。这时我们需要分析 Tomcat 是怎么处理 AJP 协议的了。为什么 requestPath 的值可以和实际 Tomcat 返回的文件路径不一致。这里就到了这个漏洞的关键所在。
漏洞的关键
这个漏洞的关键就是在
AjpProcessor中的prepareRequest()方法存在漏洞,可以让攻击者通过控制AJP协议报文的请求内容,来为request对象设置任意的attribute。
我们来分析一下这个方法。
首先要知道 AJP 的请求数据包存在 AjpMessage 的 buf 字段中,可以对比一下这个字段和上面 wireshark 抓包的内容是一致的。
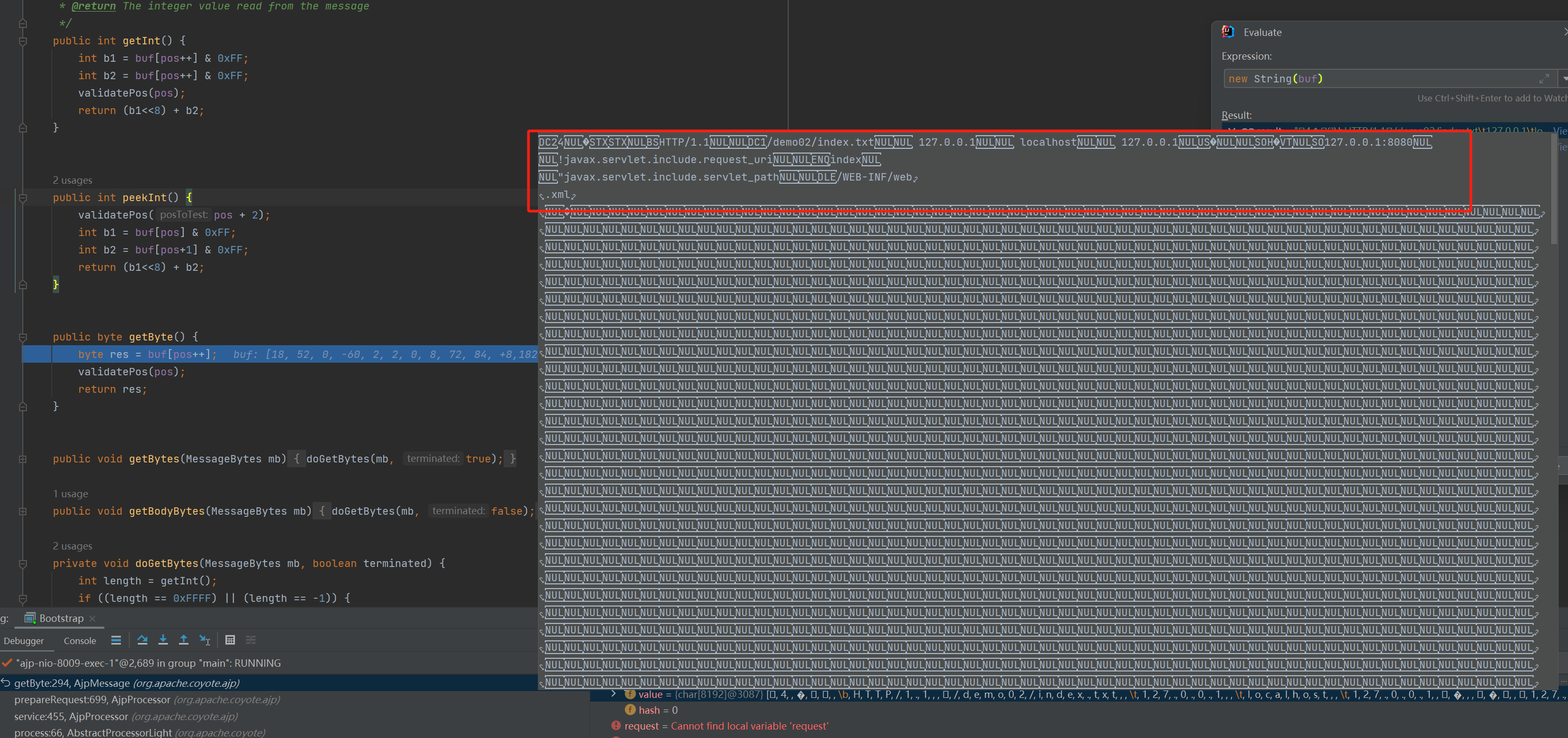
prepareRequest() 这个方法主要是在处理 AJP 数据包(也就是处理 ApiMessage 的 buf 字段),将其信息存到 request 中。
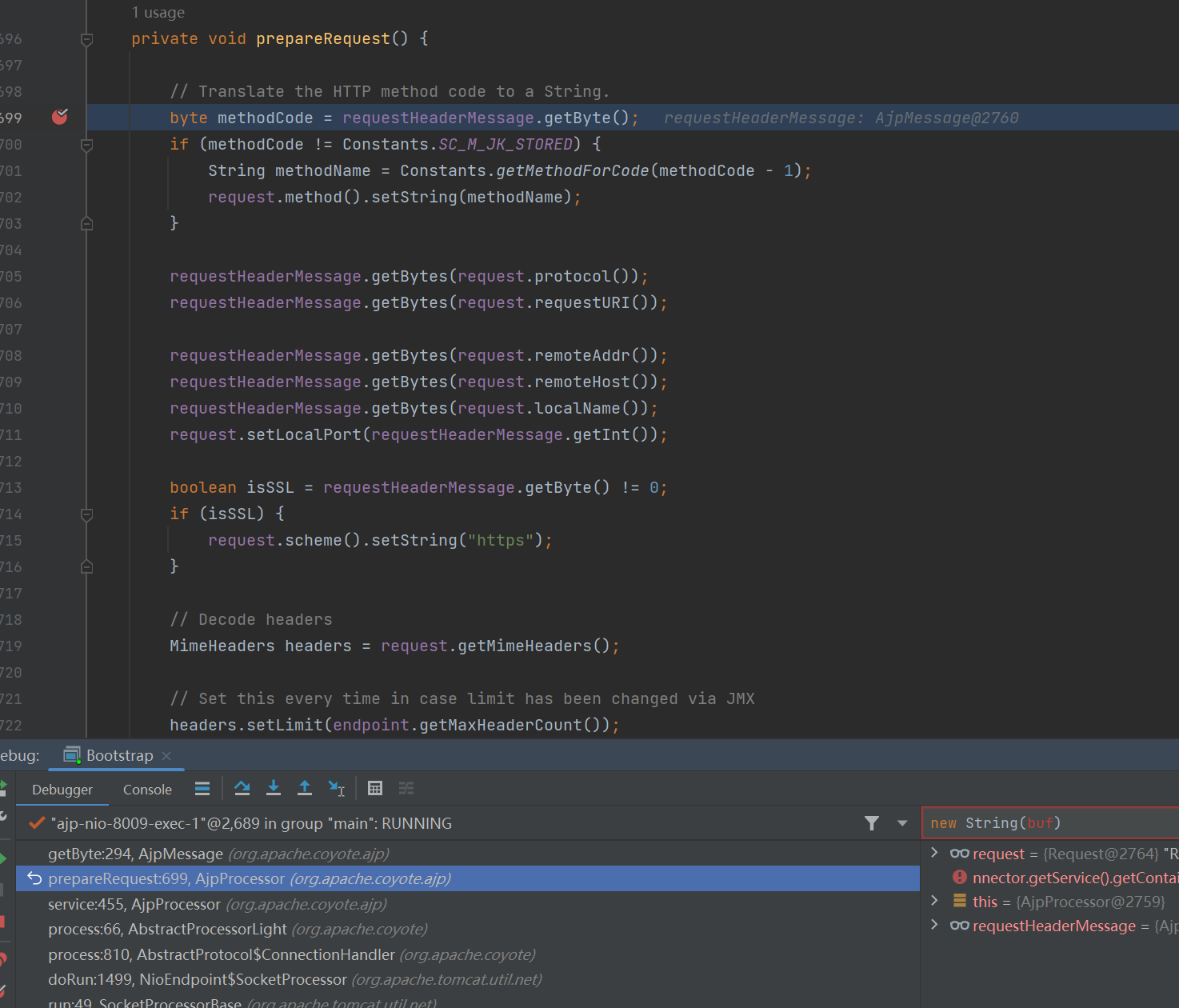
在这个方法的末尾会根据数据包中的内容对 request 的 attribute 赋值,而且没有任何过滤。这样我们就可以控制 request 的 attributes 属性。
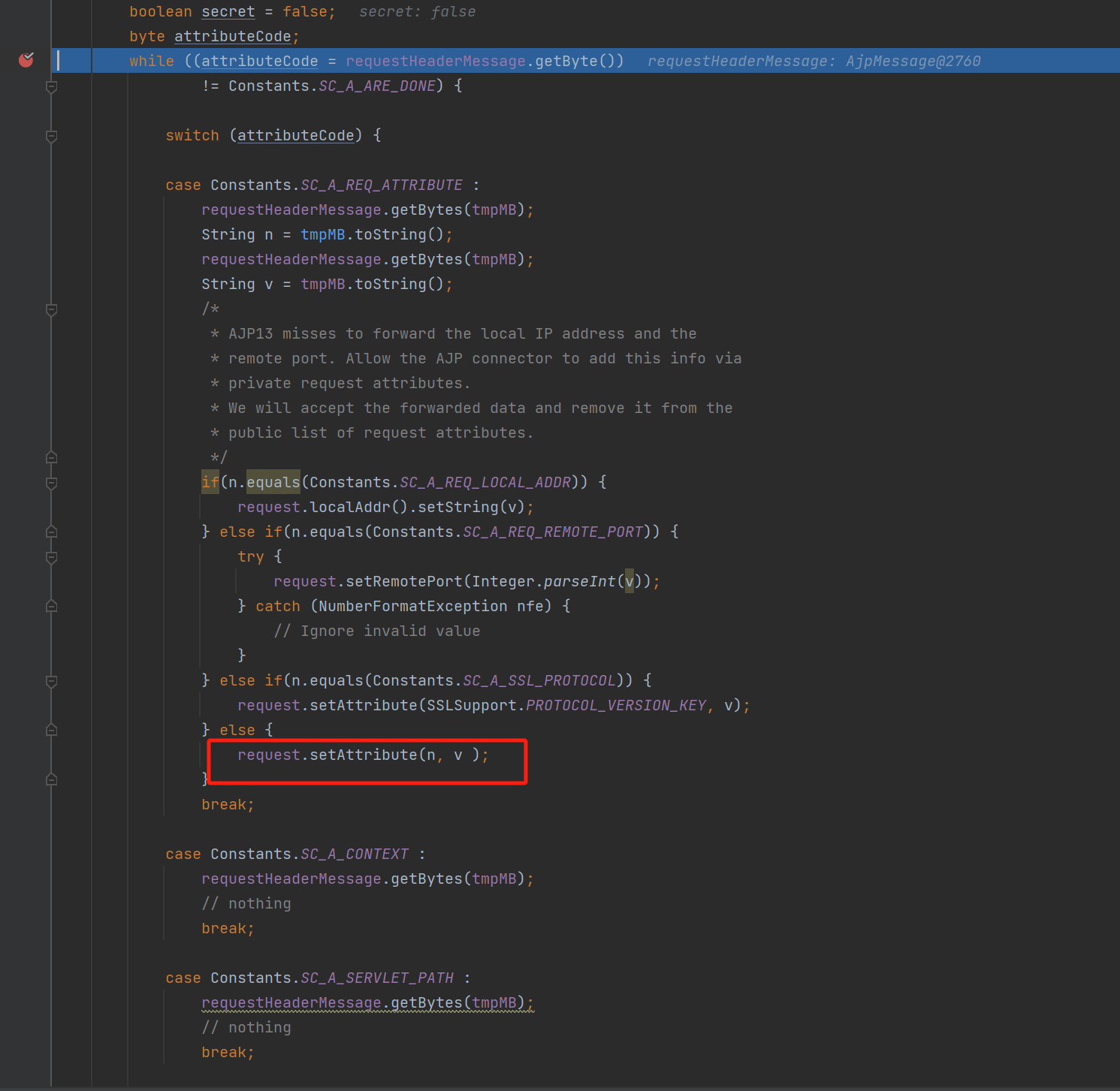
而正好在 DefaultServlet 的 getRelativePath() 中,如果 request.getAttribute(RequestDispatcher.INCLUDE_REQUEST_URI) 的值不为 null ,就会返回 servletPath = (String) request.getAttribute(RequestDispatcher.INCLUDE_SERVLET_PATH) 的值,然后读取这个值对应的文件。
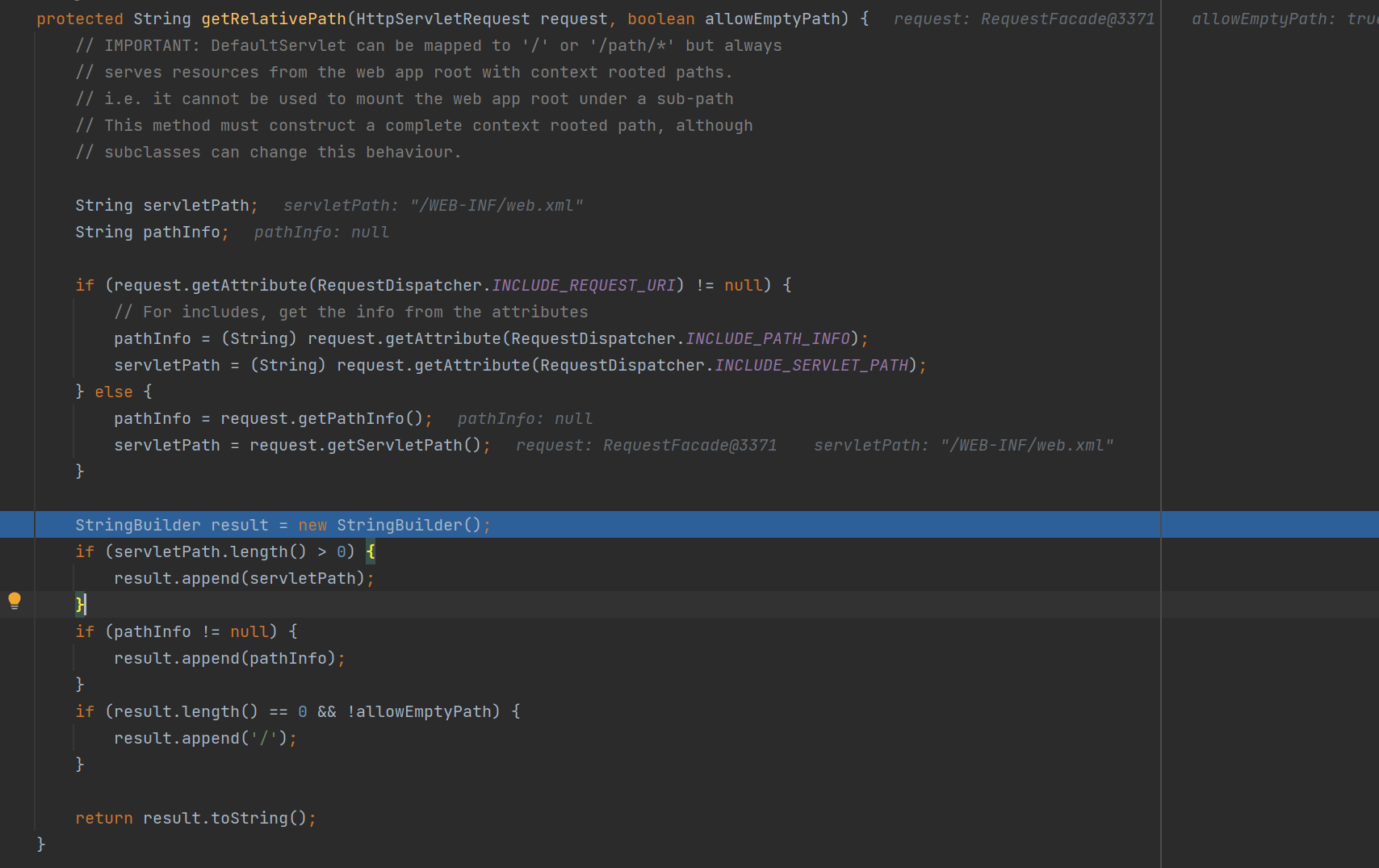
这样两个 gadget 合在一起就造成了任意文件读取漏洞。这里由于在读取文件的时候会判断文件路径是否合法,从而无法通过 ../ 来读取 webapps 目录外的内容。
介绍完了文件读取漏洞,我们再看看是怎么完成文件包含漏洞的。
文件包含命令执行
通过抓包,我们发现 poc 唯一的变化就是 URI ,将原来的 index.txt 改为了 index.jsp 。
我们再来跟一下 Tomcat 的流程,由于这次是命令执行,因此我们把断点打到 Runtime.exec() 方法的开头。
发现这次不再是利用 DefaultServlet 来读文件了,而是利用 JspServlet 来编译攻击者指定的文件,即使文件的后缀名不为 jsp 。
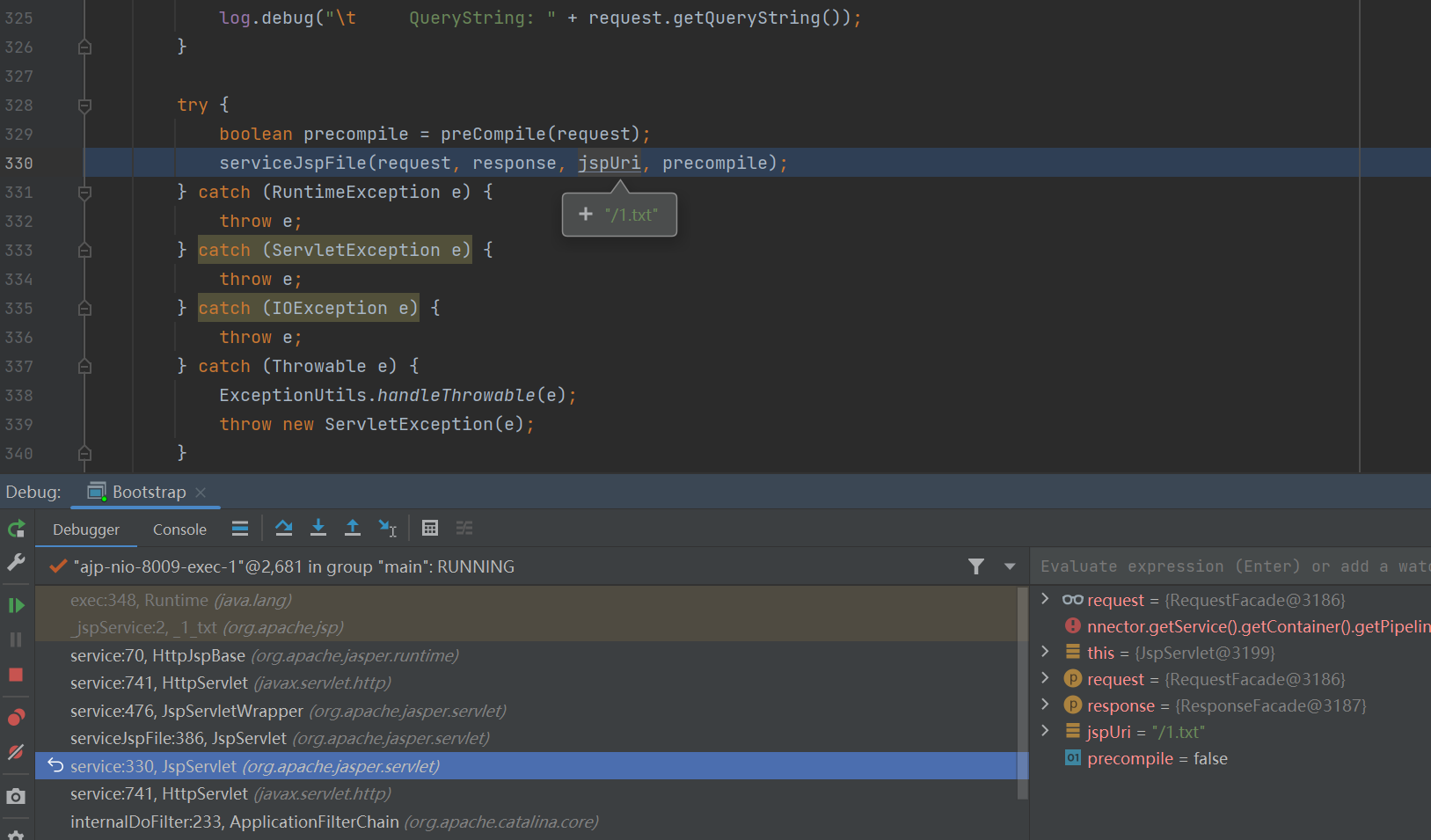
这里包含的逻辑是如果 jspUri 为 null ,那就从 request.getAttribute(RequestDispatcher.INCLUDE_SERVLET_PATH) 中获取值来编译。如果后面的值还为 null ,就通过用户请求的 URI 来获取要编译的 jsp 文件。所以用户正常访问时,代码应该走到 else 中,这里我们通过让 request.getAttribute(RequestDispatcher.INCLUDE_SERVLET_PATH) 不为 null ,从而没有走到 else 语句中。
1 |
|
Tomcat如何判断某次请求交给哪个Servlet处理
那 poc 是怎么控制请求是走到 JspServlet 中还是 DefaultServlet 中呢?这就要看 Tomcat 是怎么分发请求的。这里的核心逻辑在 org.apache.catalina.mapper.Mapper#internalMap() 中。
这个方法的主要作用就是在判断某次请求对应的
host,context和mapper,并将其封装到request中,以便后续通过pipeline的机制依次调用。
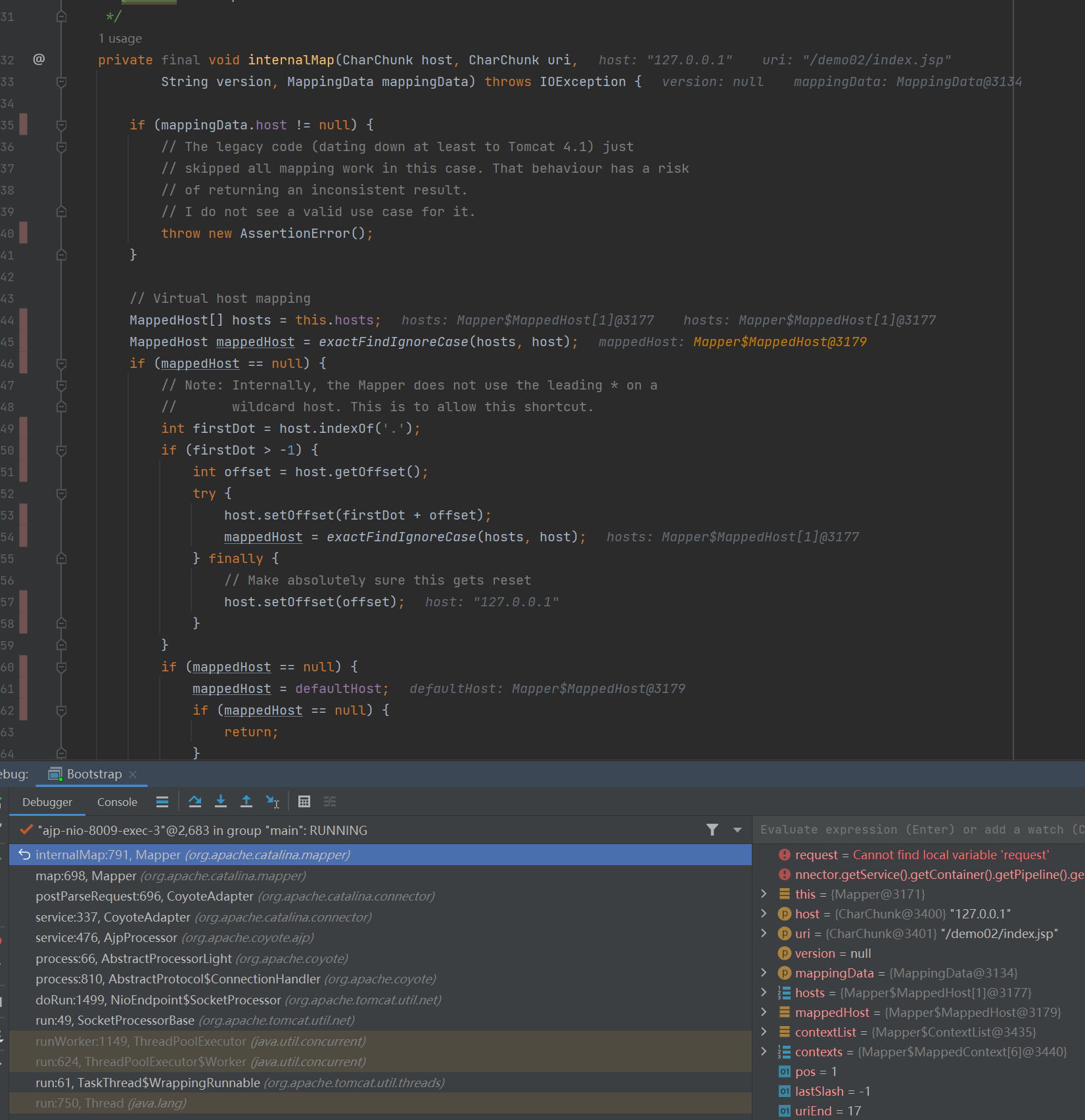
这个方法首先根据 request 的 host 字段来判断这次请求对应的 Host ,Tomcat 往往只有一个 Host ,因此这里的逻辑就不细说了。
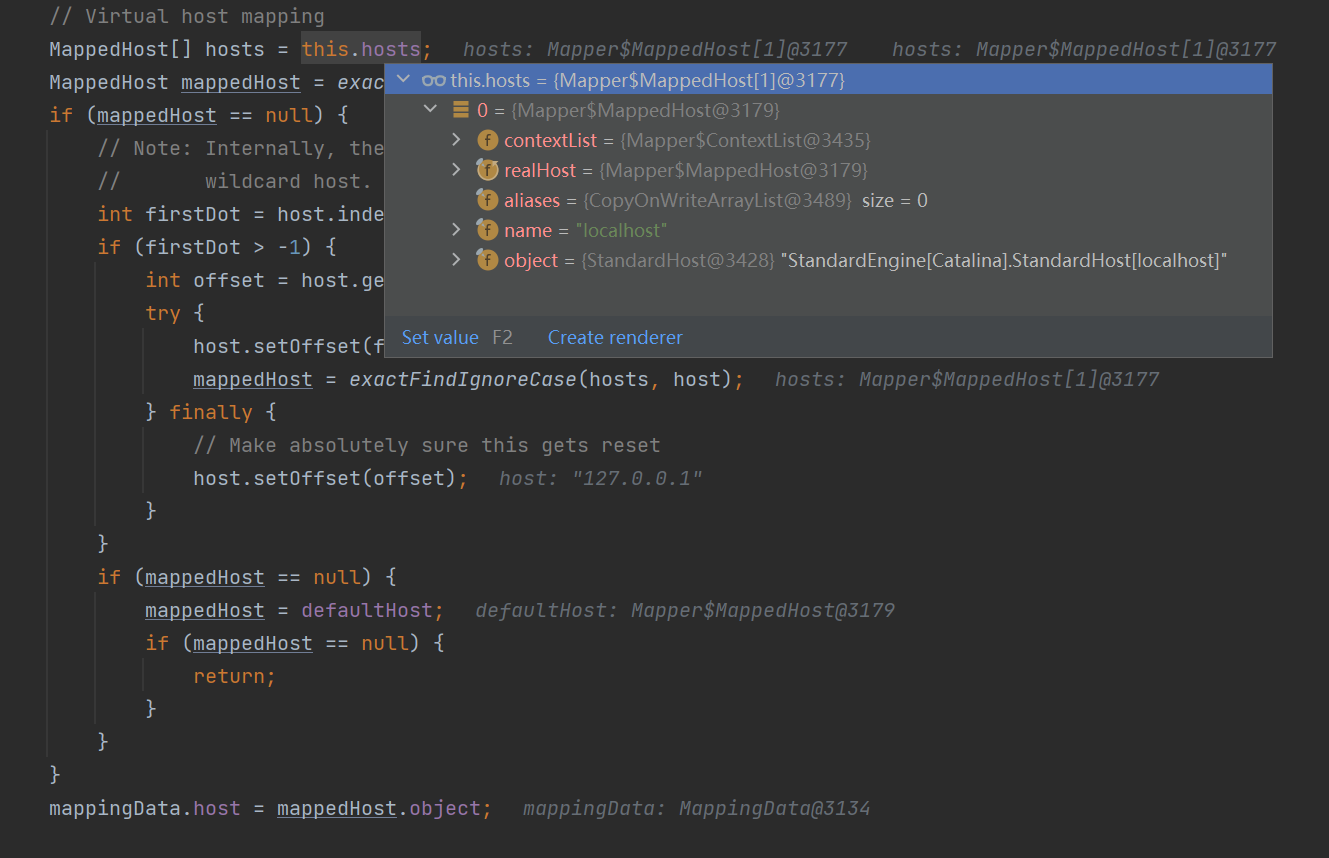
然后是根据 request 的 uri 来判断这次请求对应的 Context ,也就是访问的是 webapps 下面部署的哪个项目,因为 Tomcat 是可以同时部署多个项目的。这里判断的逻辑是 uri 的开头。
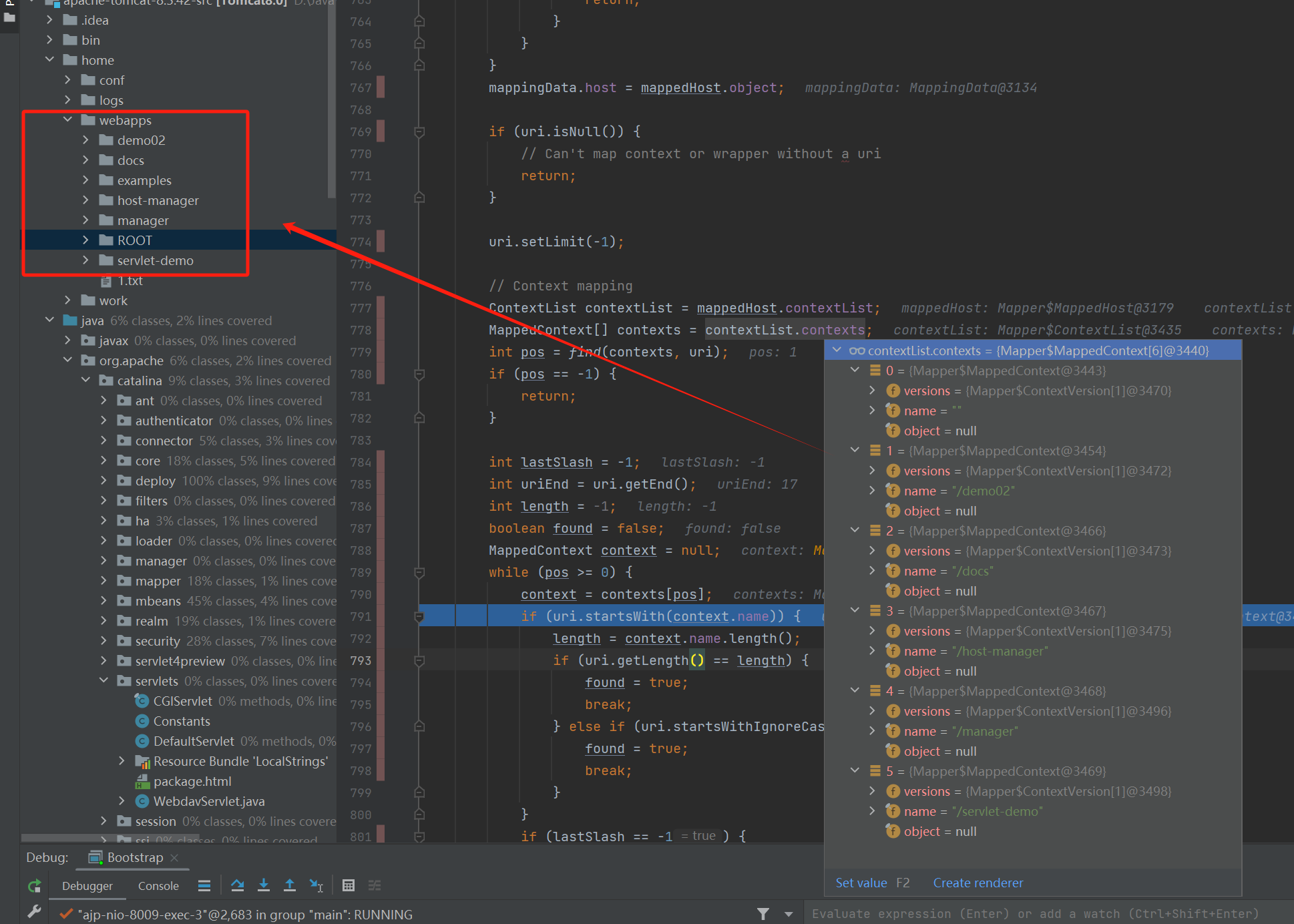
然后专门将判断某次请求对应的 Mapper (也就是这次请求交给哪个 Servlet 处理)封装到 internalMapWrapper() 方法中来调用,因为这一块稍微复杂点。
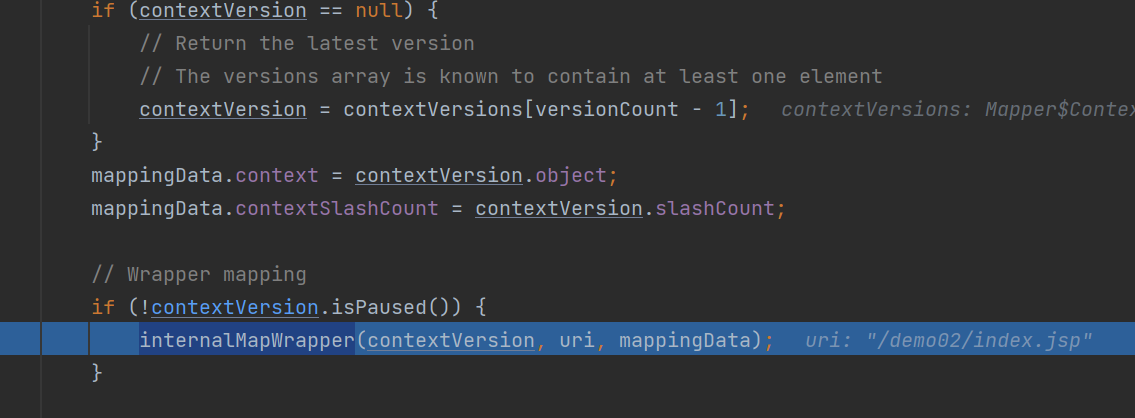
具体逻辑如下:
在 contextVersion.exactWrapper 变量中保存的是程序员自定义的且路由精确(没有通配符)的 Servlet ,Servlet 匹配的路径存在 name 变量中。
在 contextVersion.wildcardWrapper 变量中保存的是程序员自定义的且有通配符的 Servlet ,Servlet 匹配的路径存在 name 变量中。
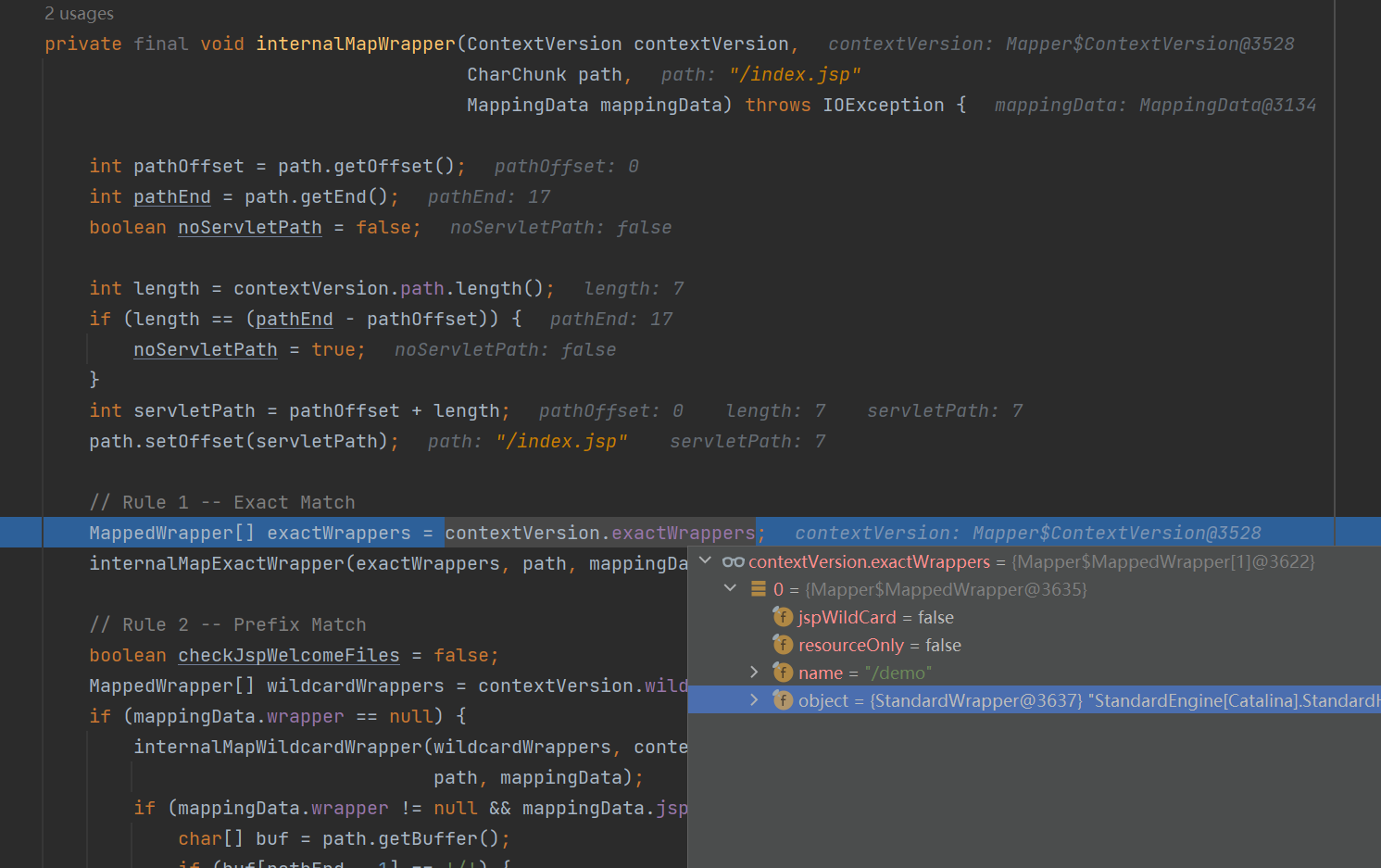
然后按照下面的顺序进行判断(在源码的注释中也写的很清楚了),一旦匹配成功就不会再进行后面的匹配了:
- 先精确匹配,判断
servletPath是否有和程序员自定义的且路由精确的servlet路径是一样的,如果是则调用对应的Servlet进行处理。 - 再通配符匹配,判断
servletPath是否有和程序员自定义的且是通配符匹配的servlet路径是一样的,如果是则调用对应的Servlet进行处理。 - 再判断
servletPath的后缀是否为jsp或者jspx,如果是则调用JspServlet进行处理。 - 再判断
servletPath是否Tomcat的欢迎界面。 - 如果上述条件都不满足,就调用
DefaultServlet来当作静态文件处理,这就匹配了前面对DefaultServlet中会读webapps目录下的文件的解释。
总结
到这里就很清楚了,第一次文件读取攻击是通过触发 Tomcat 调用 DefaultServlet 处理,来读取并返回攻击者指定的任意 webapps 目录下的文件,从而可以读取网页在 WEB-INF 目录下的源码。第二次文件包含攻击是通过修改 AJP 数据包中的 URI 字段以 jsp 结尾,触发 Tomcat 调用 JspServlet 处理,来编译攻击者指定的任意文件,从而命令执行。
而两者的造成都是因为 AjpProcessor#prepareRequest() 方法中对 request 的 attributes 赋值没有任何限制,造成黑客在 Tomcat 调用 DefaultServlet 和 JspServlet 进行处理的时候携带了恶意的参数。
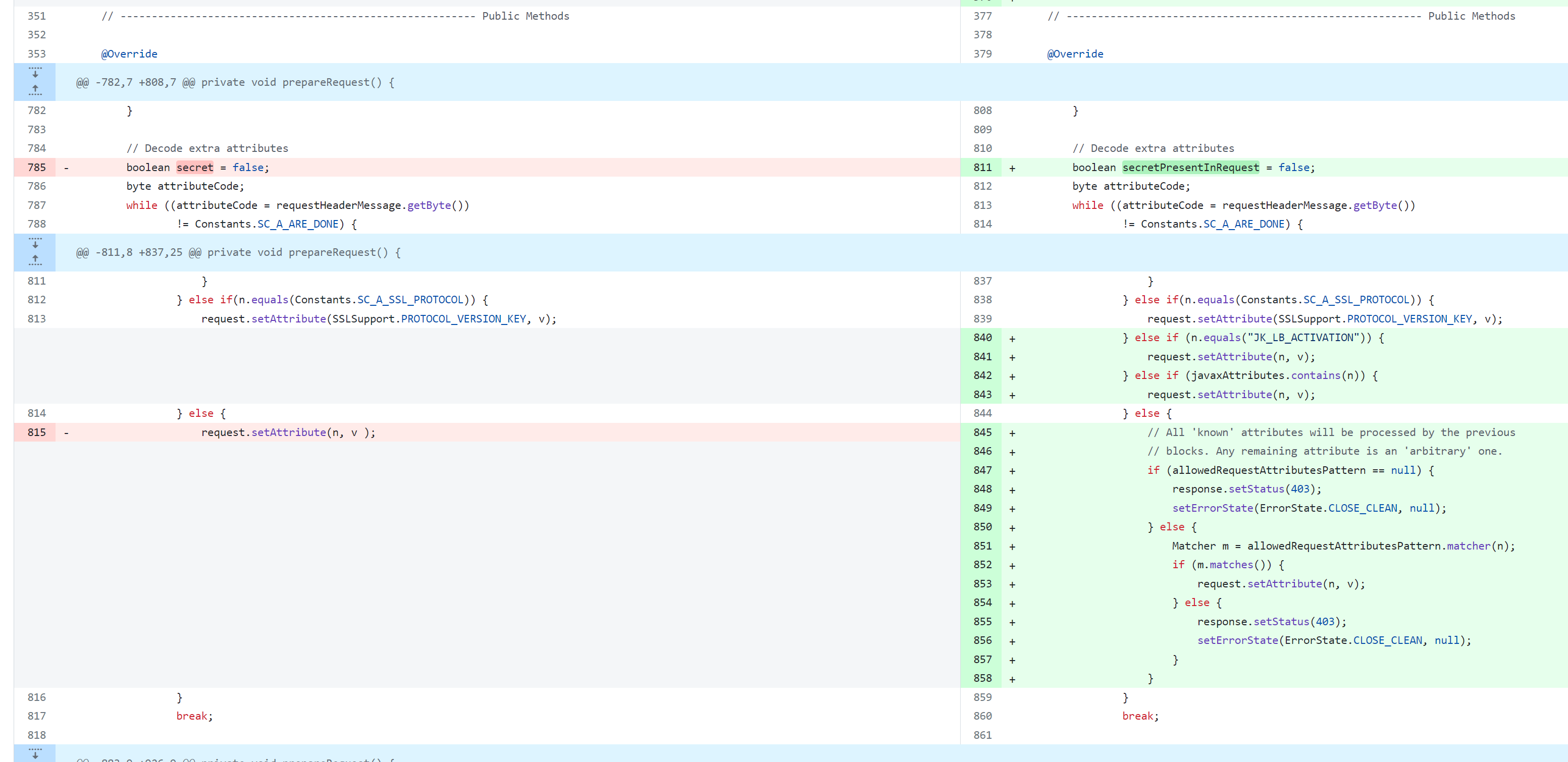
漏洞修复
在 AjpProcessor#prepareRequest() 方法中做了对 request 的 attributes 赋值的限制。现在只能对特定的 attribute 进行控制。
修复后的代码:
1 | else { |
参考文章
https://tomcat.apache.org/connectors-doc/ajp/ajpv13a.html
https://httpd.apache.org/docs/2.2/mod/mod_proxy_ajp.html
https://www.00theway.org/2020/02/22/ajp-shooter-from-source-code-to-exploit/
https://mp.weixin.qq.com/s/GzqLkwlIQi_i3AVIXn59FQ





