java序列化后的二进制格式分析
说明
在阅读后面的内容时,这里先要提前准备好两个工具:
- 下载 https://github.com/NickstaDB/SerializationDumper 工具来可视化二进制的序列化数据的结构。
不过这个工具的运行需要传入二进制文件的十六进制表示。因此使用前我们需要用下面的python脚本处理一下,将二进制文件的内容读取出来,并以十六进制的格式输出。
1 | import binascii |
使用方式: java -jar SerializationDumper.jar <十六进制字符串> 。
idea下载BinEd - Binary/Hex Editor插件来查看和编辑二进制文件。这里使用010 editor也是可以的。
此外,
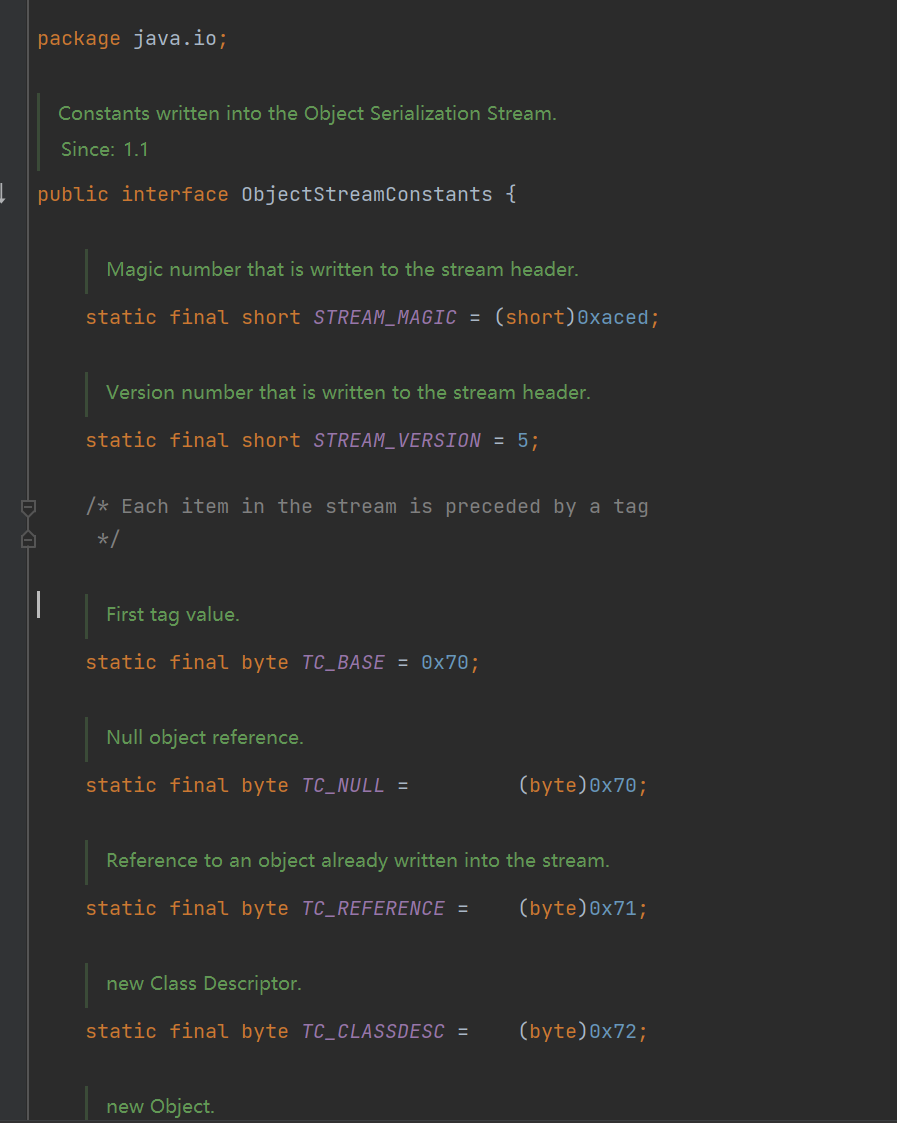
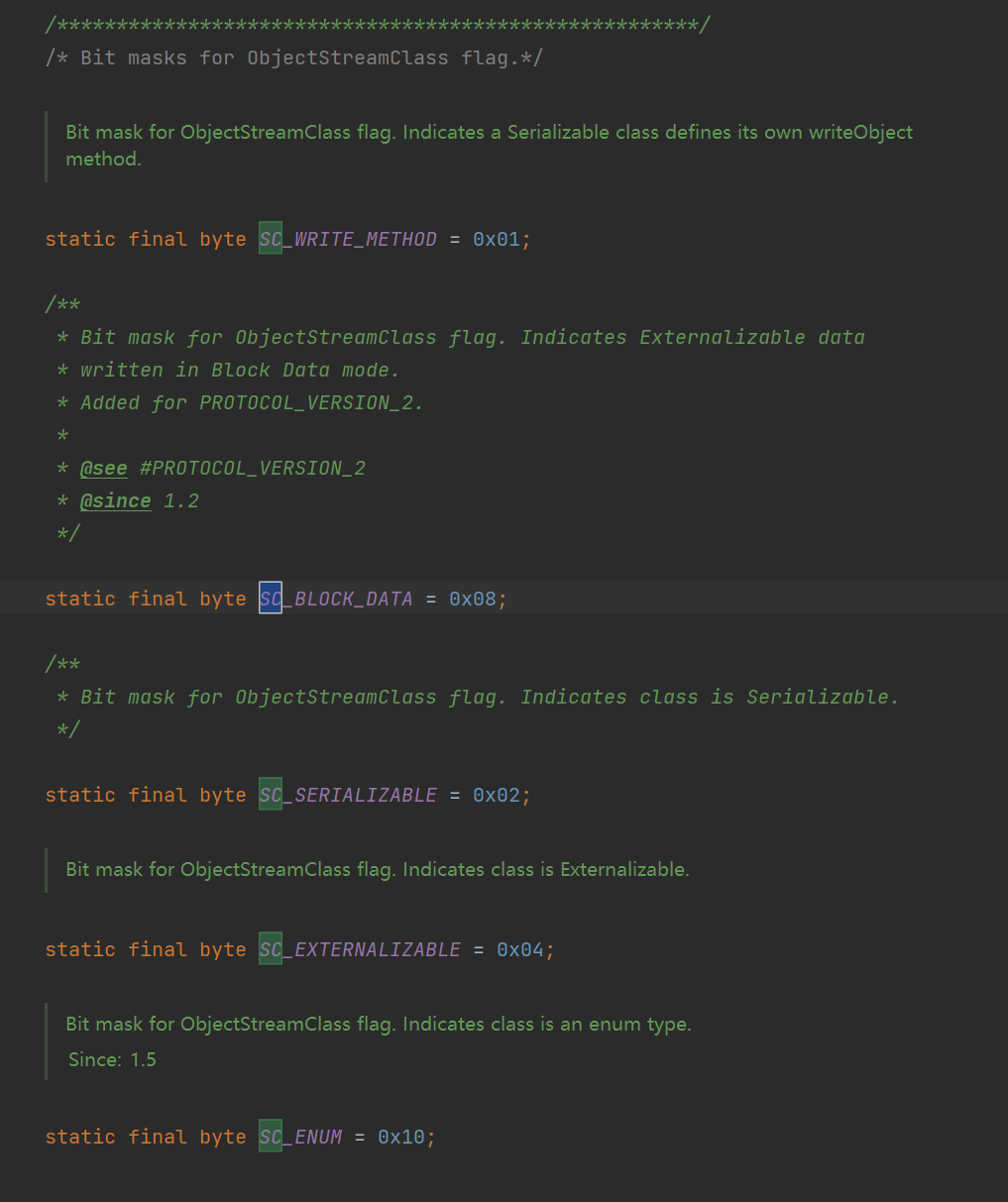
java序列化使用到的常数定义在ObjectStreamConstants接口中,后面会用到。
示例分析
示例一
1 | package com.just.demo1; |
1 | package com.just.demo1; |
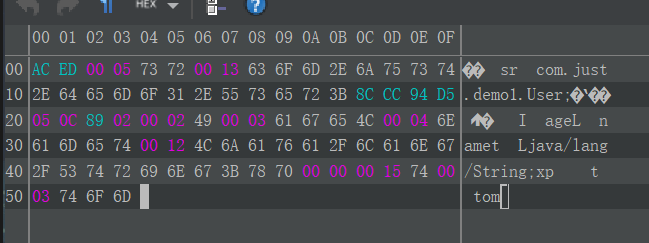
序列化得到的二进制文件用上面提到的 idea 插件打开样式如下:
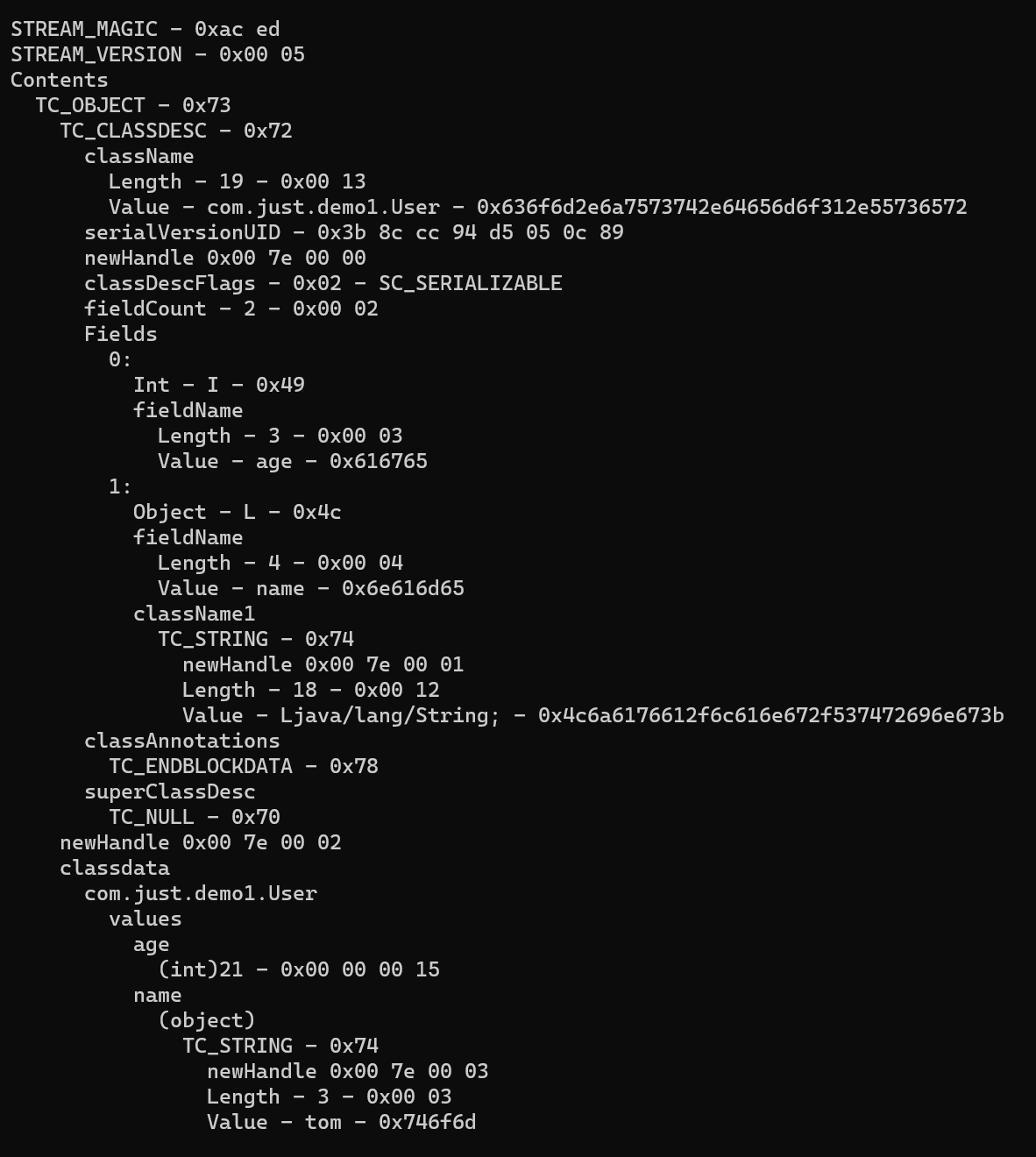
再用上面的第一个工具分析其结构:
接下来我们逐字节详细的分析序列化得到的二进制内容。
刚开始的两个字节 ACED 是 jdk 原生序列化后二进制流固定的魔数,用于判断这个二进制流是否是 jdk 原生的序列化数据。对应 STREAM_MAGIC 。
接下来的两个字节 0005 用于表示流协议的版本。对应 STREAM_VERSION 。大多数情况都是 0005 。
再接下来的一个字节 73 表示序列化的是一个对象。对应 TC_OBJECT 。举个其它的例子,如果序列化的是一个字符串类型,则这个字节应为 TC_STRING ,对应 74 。
后面的一个字节 72 标识对象的类描述信息的开始,就是说下一个二进制块的内容是类描述信息。对应 TC_CLASSDESC 。
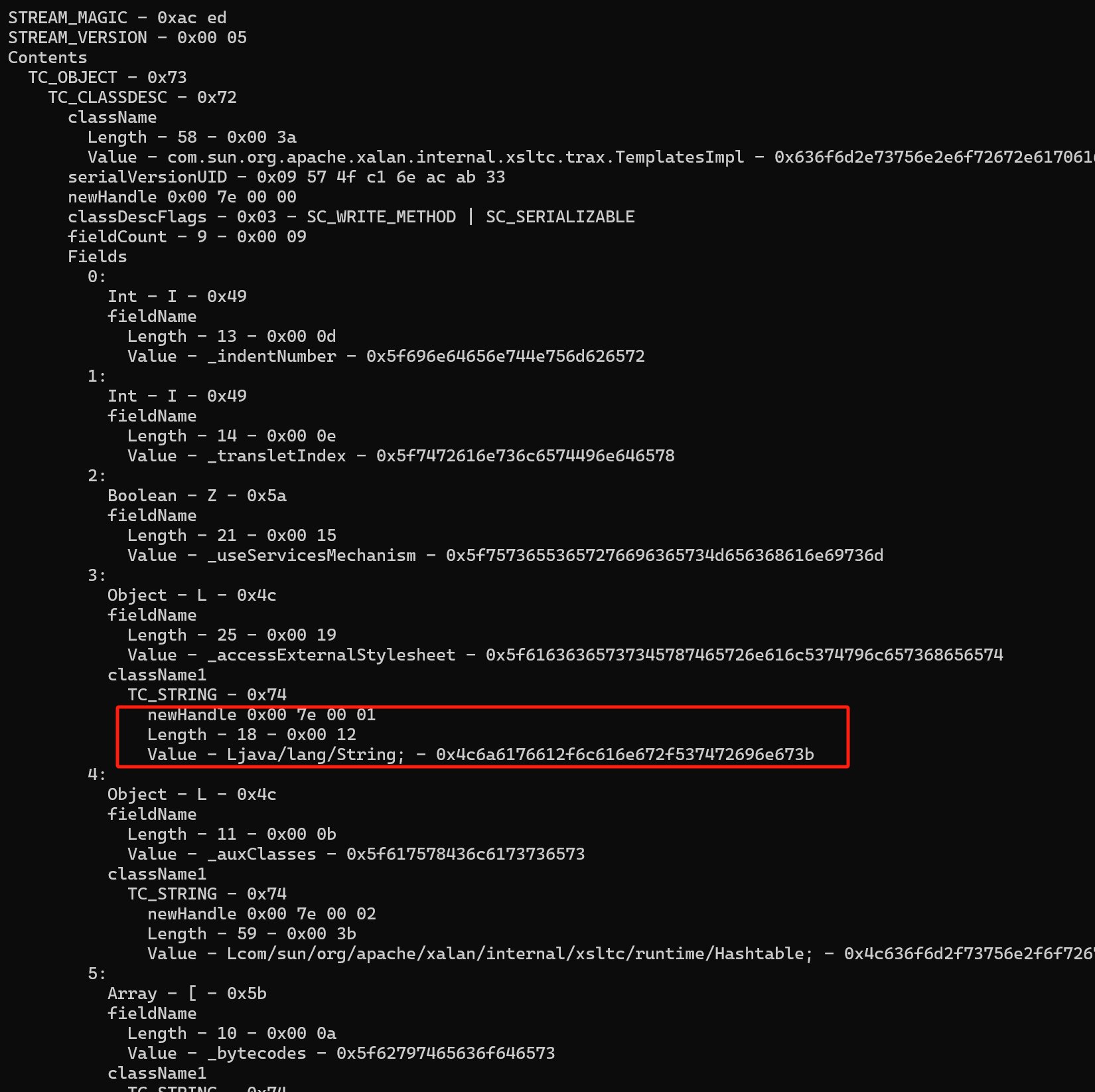
再后面的两个字节 0013 表示对象类全名的长度为 19 ,然后再后面就是类全名 com.just.demo1.User 。
再后面的八个字节表示的是当前对象中定义的 serialVersionUID 值。代码中的定义如下:
1 | private static final long serialVersionUID = 3208092597671621268L; |
其值 3208092597671621268 转换成十六进制的值就是:2C 85 6F 38 6A C6 F2 94 ;需要注意的是 如果一个类中没有定义该值系统会自动生成一个新的值 ,在二进制序列中追加在此处,因为 serialVersionUID 的类型是 long 类型的,所以它占用了 8 个字节,所以系统自动生成的时候也会自动创建一个 long 类型的数据【 8 个字节的二进制序列】。
接下来的一个字节 02 表示这个对象是实现了 Serializable 接口的。
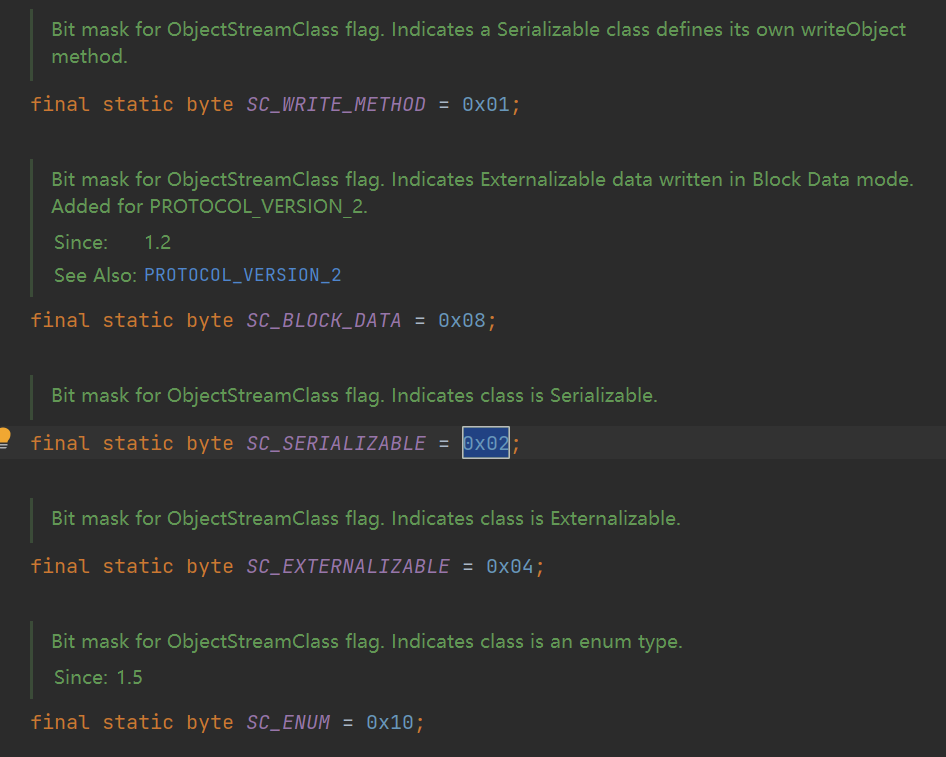
再接下来的两个字节 0002 表示这个对象序列化了的属性的数量。也就是没有被 transient 关键字标识了的属性的数量。
再后面就是这两个属性的信息:
1 | // 第一个字段age的信息 |
第一个字段的第一个字节转换会字符是 I ,表示这个字段是 int 类型的,然后后面的两个字节 00 03 表示字段名的长度为 3 ,然后 61 67 65 就是字段名的 ASCII 码。
第二个字段同理,4C 转化为字符是 L ,表示这个字段是引用类型(非基本类型)的,然后后面的两个字节 00 04 表示字段名的长度为 4 ,然后 6E 61 6D 65 就是字段名的 ASCII 码。由于这个字段是引用类型的(被标识了 L ),那么后面还需要一块内容来标识这个引用类型的类。也就对应后面的 74 00 12 4C 6A 61 76 61 2F 6C 61 6E 67 2F 53 74 72 69 6E 67 3B 。开头的 74 为 TC_STRING ,也就是说后面的内容是字符串。然后 00 12 标识字符串的长度,然后一直到最后就都是字符串本身。这里的字符串就是前面引用类型的类全名 Ljava/lang/String; 。记得注意结尾的分号。
到这里就结束了类字段信息的部分。后面的 78 即 TC_ENDBLOCKDATA ,标识这段内容的结束。70 即 TC_NULL ,标识这个类没有父类。这里是不考虑 Object 类的。
最后一块内容就是类字段的具体值。第一个字段是 int 类型的,占四个字节,就是 00 00 00 15 表示 age 字段的值为 21 。第二个字段是 String 类型的,就需要开头用 74 来标识,然后是字符串的长度和字符串的具体值。
示例二
再看一个稍微复杂一点的案例。
1 | package com.just.demo2; |
1 | package com.just.demo2; |
1 | package com.just.demo2; |
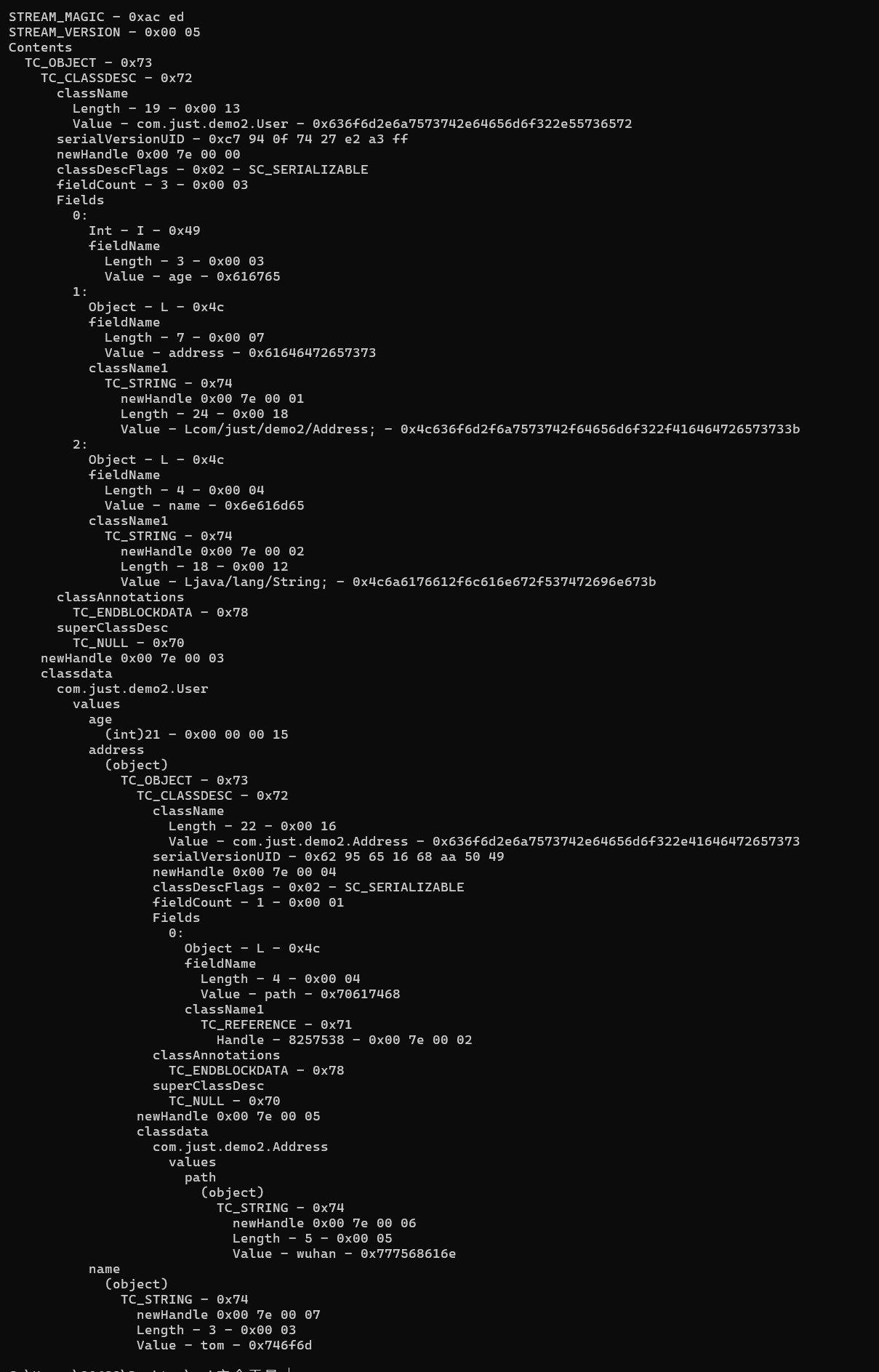
这里开头固定的结构和前面一样就不细说了,直接到类字段结构的一部分。
1 | // 序列化二进制流的魔数 |
类字段结构关键的部分就是要注意基本类型的结构不需要后面标识类名的一部分。
基本类型字段的结构:
1 | <标识类型的一个字节> <字段名字的长度> <字段名字> |
而引用类型会多后面一部分:
1 | <标识引用类型的一个字节L: 0x4C> <字段名字的长度> <字段名字> <TC_STRING: 0x74> <字段类型全类名的长度> <字段类型全类名> |
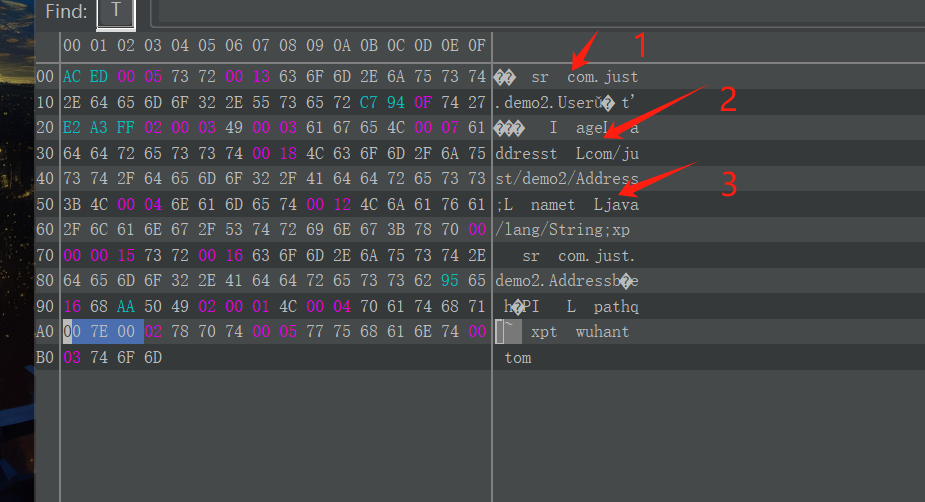
示例二的具体分析如下:
1 | // 表示这个对象序列化了三个字段 |
接下来的是一个关键。
71 表示 TC_REFERENCE 。
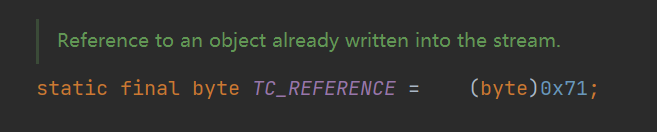
根据注释我们可以知道,这个标识的作用是引用已经写入序列化流中的对象类名,以免多次写入同一个类的类名导致序列化的结构的内容有没必要的部分。
TC_REFERENCE 标记之后,是一个整数 Int 类型的数据,也就是说它占四个字节,它生成的基数是00 7E 00 00 ( baseWireHandle 常量)。
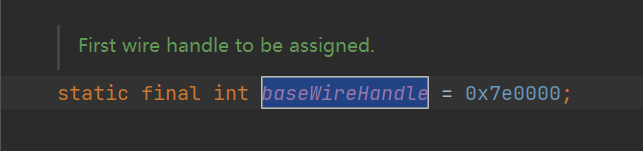
这个数据减去 baseWireHandle 常量的值再加一表示的是这个引用是在序列化流中的第几个声明过的。比如这里是 00 7E 00 02 ,就说明这个引用的是第三个声明的类( java.lang.String )。可以在使用第一个工具的时候发现其在声明每个类的时候已经标注了其的 handle 信息。
关于这里
handle的定义说的更清楚一些:一个写入字节流的对象都会被赋予引用Handle,并且这个引用Handle可以反向引用该对象(使用TC_REFERENCE结构,引用前面handle的值),引用Handle会从0x7E0000开始进行顺序赋值并且自动自增,一旦字节流发生了重置则该引用Handle会重新从0x7E0000开始。
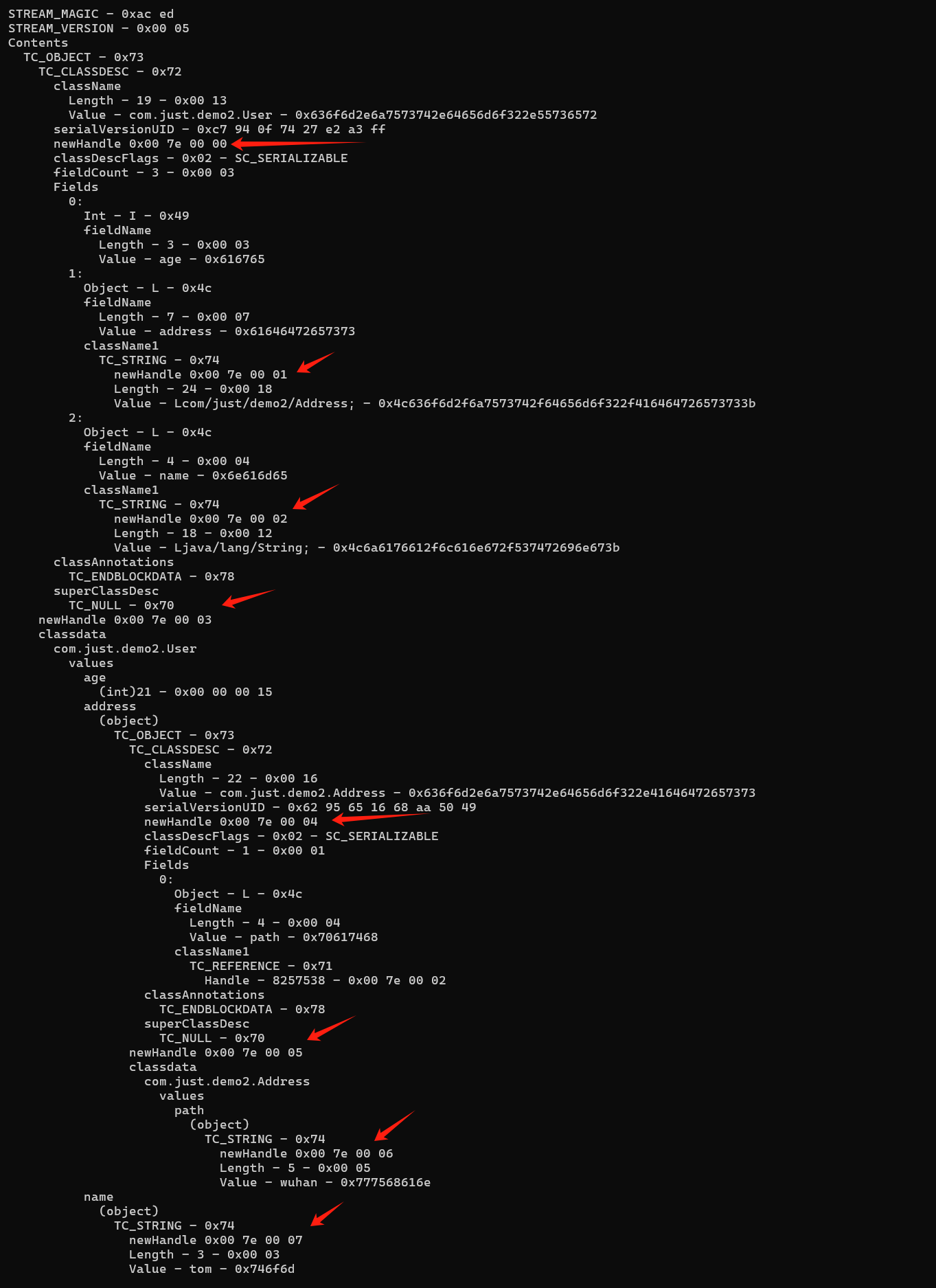
然后就是常规的 78 ( TC_ENDBLOCKDATA ),70 ( TC_NULL )。最后就是两个字段的值。
1 | // TC_STRING |
示例三
最后看个 java 反序列化漏洞中常用的 TemplatesImpl 类来序列化分析分析。
1 | package com.just.demo3; |
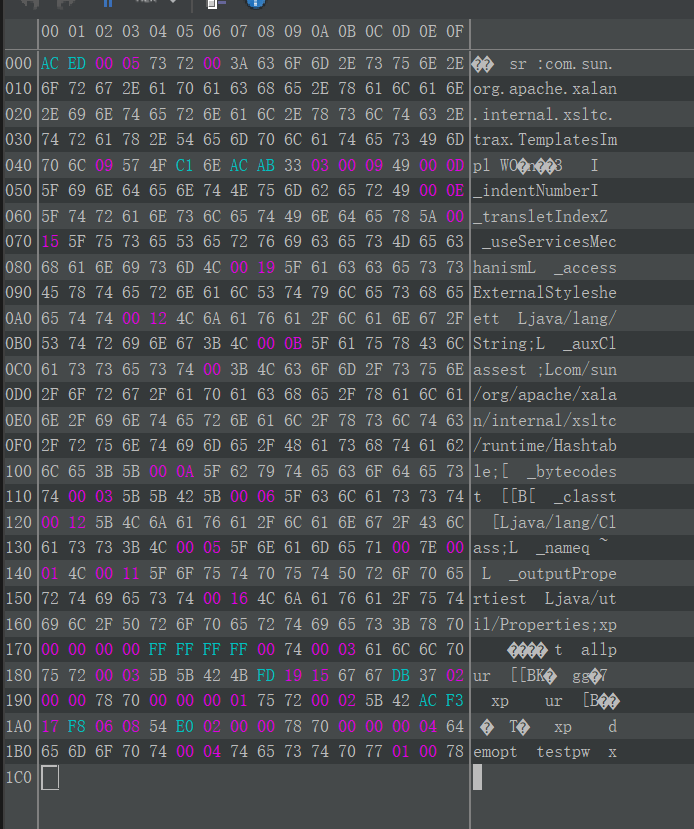
这里比较长,就只分析和前面不同的地方。
首先看到 serialVersionUID 的下一个部分,这里是 03 。
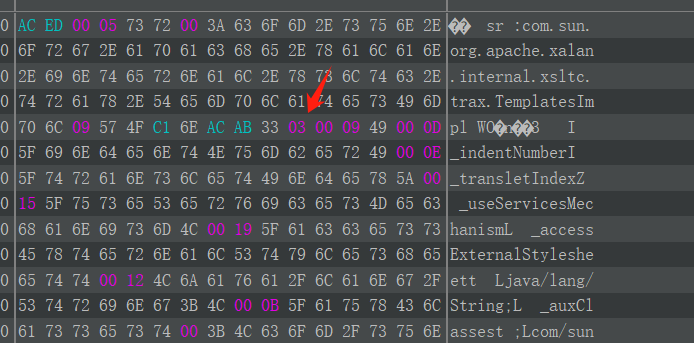
03 在 ObjectStreamConstants 中找不到直接的对应,它其实是 SC_WRITE_METHOD | SC_SERIALIZABLE 的结果,表示这个类重写了 writeObject() 并且实现了 Serializable 接口。这也就是说,如果一个类满足多个 SC_XXXX ,那这一位应该是这些 | 后的结果。这在使用 SerializationDumper 工具的时候也可以看出来。
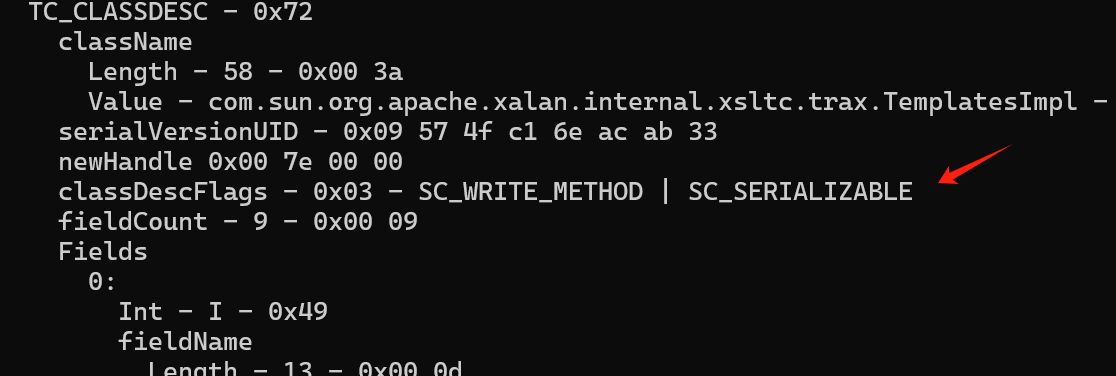
然后就是 9 个序列化了的字段:
1 | int(49) _indentNumber |
第六个字段 _bytecodes 比较特殊,是 byte[][] 类型的。
 关注蓝色这个部分。
关注蓝色这个部分。
首先是 5B 表示这个字段是数组类型的。然后是末尾的 5B 5B 42 ,其中两个 5B 表示这是二维数组,42 表示是 byte 类型的。
第七个字段 _class 也是类似的。开头的 5B 表示这个字段是数组类型的,末尾是一个 5B 开头的,说明其是一维数组,然后后面跟的就是其数组存放的元素类型。
这里可能会感觉有点问题,当字段是数组时,开头的标识都是
5B,那怎么区分末尾的元素类型是基本类型还是引用类型的呢。这里我猜可能是通过根据引用类型的开头是L来区分的,这可能就是引用类型需要L开头的原因。
倒数第二个字段也比较特殊,不过前面在示例二中提到了。这里用到了反向引用 TC_REFERENCE ( 0x71 ),后面跟的 00 7e 00 01 相对 baseWireHandle 的偏移是 1 ,说明其引用的是第二个流中声明过的引用类型,也就对应的是 Ljava/lang/String; 。
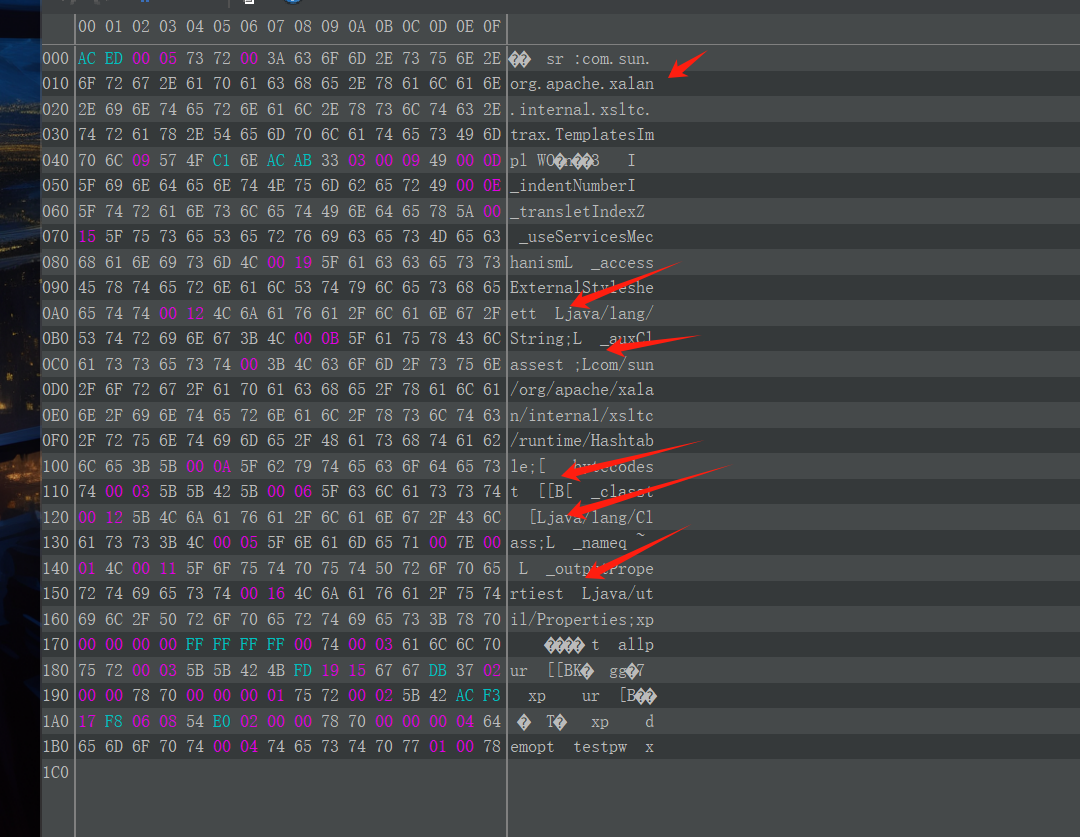
然后依次是 9 个字段的值:
1 | // int: 0 |
然后就是一个新的标识: TC_ARRAY ( 0x75 )。表示后面需要序列化的是一个数组。然后是紧跟着 TC_CLASSDESC 。
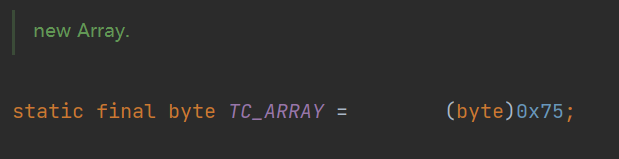
然后 00 03 是类名的长度, 5B 5B 42 是类名 [[B ,表示 byte[][] 。然后是八个字节的 serialVersionUID ,然后是 SC_SERIALIZABLE ,然后是 00 00 表示这个类有 0 个字段(如果是 TC_ARRAY 数组类型,貌似这里都是 00 00 ,毕竟数组也不是个真的类,没有验证过,感兴趣的可以试试)。由于没有字段,然后就是 TC_ENDBLOCKDATA , TC_NULL ,然后 00 00 00 01 表示二维数组的第二维的长度为 1 。
然后继续是开启内层的一维数组描述字节 TC_ARRAY ,TC_CLASSDESC 。然后 00 02 表示类名长度,5B 42 表示类名 [B ,即一维字节数组。然后继续是八个字节的 serialVersionUID ,然后是 SC_SERIALIZABLE 。依旧是 00 00 表示这个类有 0 个字段。然后是 TC_ENDBLOCKDATA , TC_NULL ,然后 00 00 00 04 表示一维数组的长度为 4 ,也就对应示例代码中的 "demo" 字符串 。然后就是 "demo" 字符串本身了( 64 65 6D 6F )。
这里就结束了这个二维字节数组字段( _bytecodes )的序列化。然后是下一个字段的值,是 TC_NULL ( 70 ),说明下个字段( _class )为 null 。
然后是 _name 字段的值 "test" 。
然后最后一个字段 _outputProperties 的值还是 TC_NULL 。
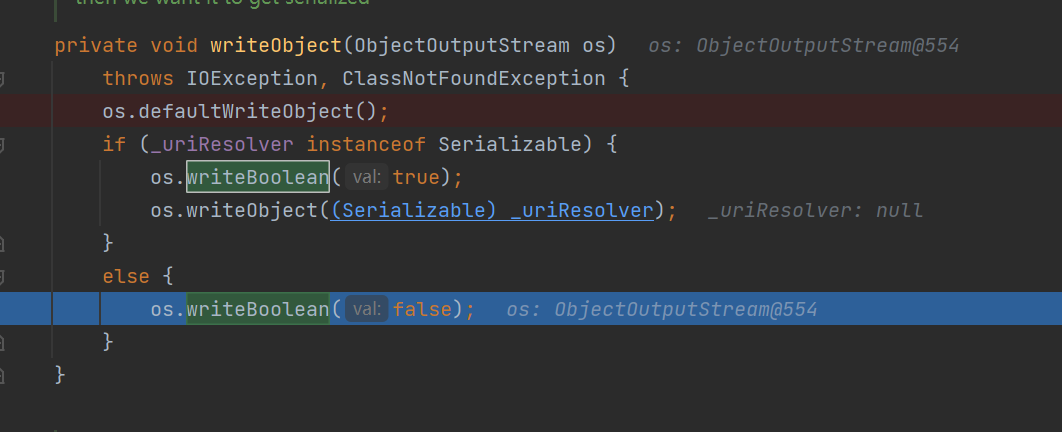
后面又是一个新的点,77 表示 TC_BLOCKDATA ,后面跟着的第一个字节表示再后一部分的长度,这里是 01 。然后再后一部分 00 表示 false 。最后以 TC_ENDBLOCKDATA 结尾。这一块其实按照常理是不存在的,这里的存在是因为 TemplatesImpl 类重写了 writeObject() 方法。在默认的序列化流程之后还调用了 writeBoolean() 方法。这一块的格式就是序列化 Boolean 数据时的格式。
总结
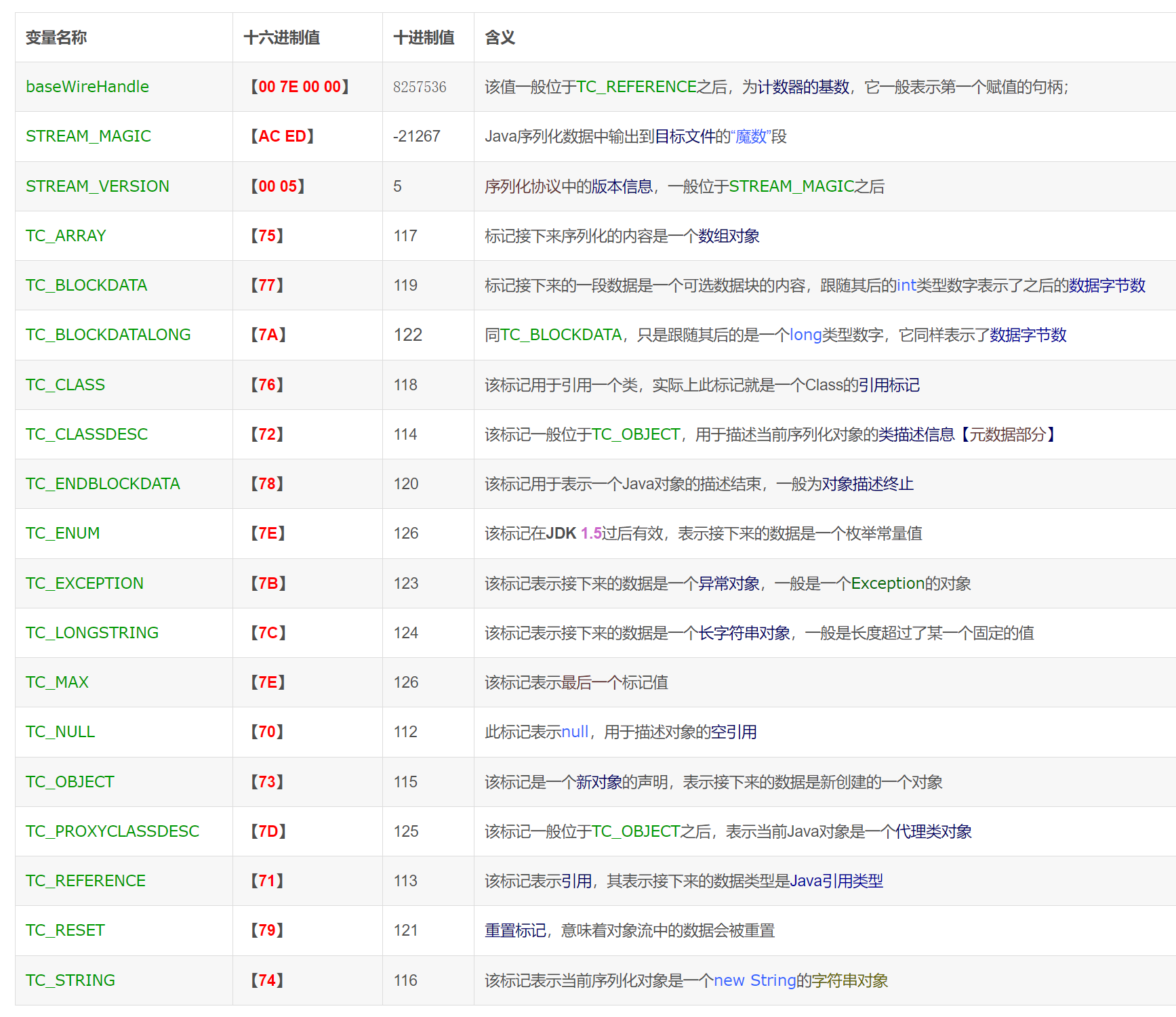
这里只是抛砖引玉来说明序列化的大致结构。更加细节的需要结合参考官方文档,源码和 SerializationDumper 工具来分析。这里基本上就能看得懂七七八八的了。后面给出一些标识的参考。
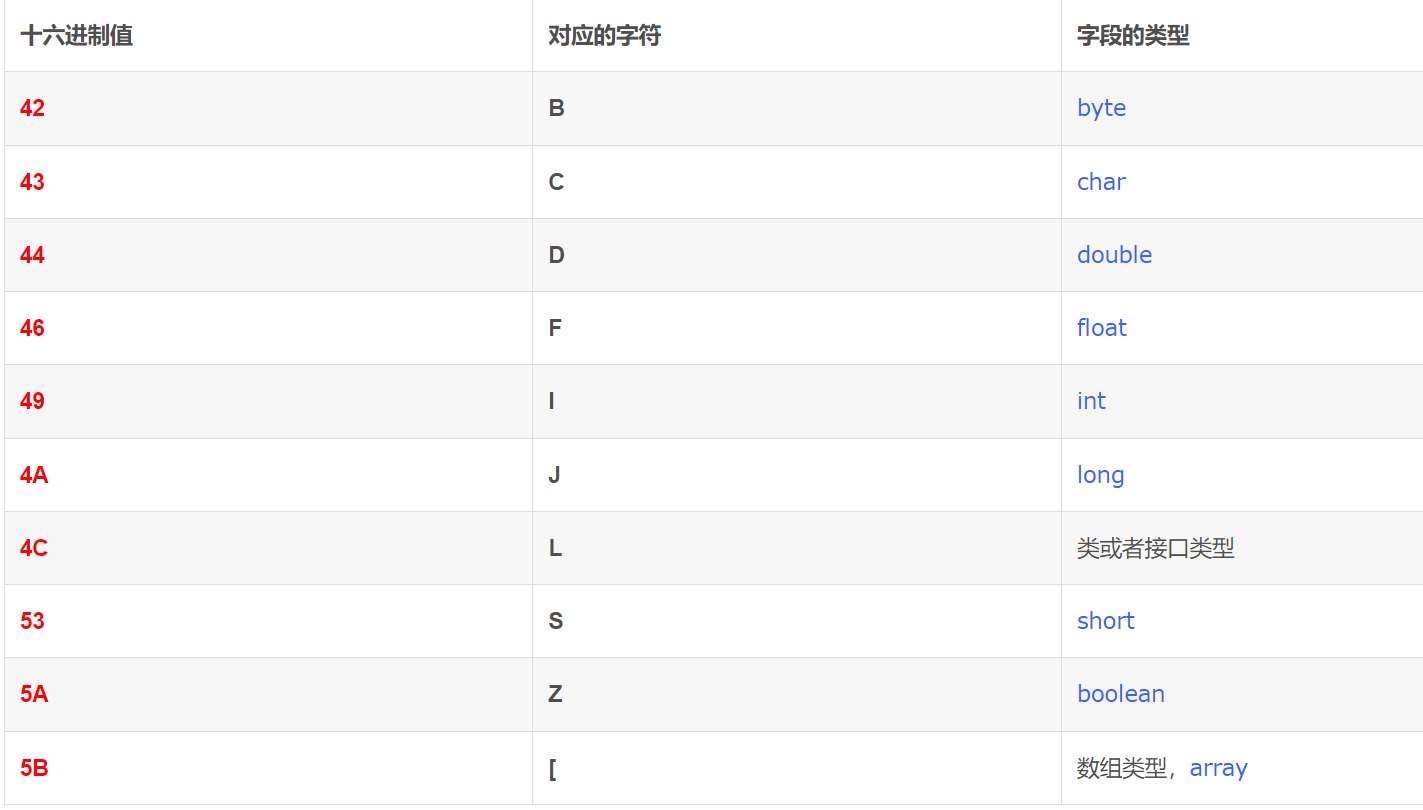
参考文章
https://blog.csdn.net/silentbalanceyh/article/details/8183849
https://docs.oracle.com/javase/8/docs/platform/serialization/spec/protocol.html





